Tóm tắt: Khai phá dữ liệu (Data Mining - DM) là khái niệm rộng và có thể gây khó khăn cho các nhà nghiên cứu không chuyên sâu về công nghệ thông tin. Điều quan trọng là phải nắm được nguyên lý, khái niệm liên quan đến DM, từ đó, định hướng mục tiêu và ứng dụng DM trong từng lĩnh vực, đặc biệt là trong lĩnh vực tài chính, ngân hàng. Bài viết này trình bày các khái niệm cơ bản về DM, ứng dụng của DM trong lĩnh vực tài chính, ngân hàng và phương pháp xếp hạng tín dụng khách hàng cá nhân trong ngân hàng dựa trên kỹ thuật cây quyết định C4.5.
Từ khóa: Học máy, DM, cây quyết định, khách hàng trung thành.
PERSONAL CUSTOMER CREDIT RATING WITH DATA MINING, C4.5-ALGORITHM
Abstract: Data Mining (DM) has so far been a broad concept and make difficulty for researchers who do not specialize in information technology. It is important to understand the principles and concepts of DM so that they can orient their goals and apply DM in each field, especially in banking and finance sector. This artical presents the basic concepts of DM, DM application in banking and finance sector, the solution of personal banking customer credit rating by C4.5 algorithm.
Keywords: Machine learning, DM, decision tree, loyal customer.
1. Tổng quan về xếp hạng tín dụng, DM và cây quyết định
1.1. Xếp hạng tín dụng
Xếp hạng tín dụng là việc đưa ra nhận định về mức độ tín nhiệm đối với trách nhiệm tài chính hoặc đánh giá mức độ rủi ro tín dụng phụ thuộc các yếu tố như năng lực đáp ứng cam kết tài chính, khả năng dễ bị vỡ nợ khi điều kiện kinh doanh thay đổi, ý thức và thiện chí trả nợ của người đi vay. Thang điểm xếp hạng tín dụng khách hàng có thể được minh họa trong Bảng 1.
Bảng 1: Điểm xếp hạng tín dụng khách hàng cá nhân
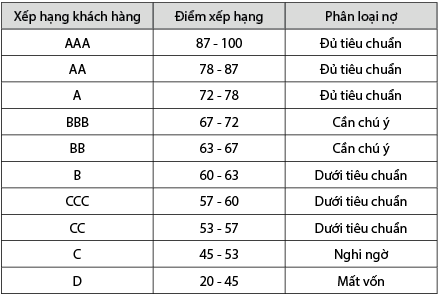
Nguồn: Ngân hàng Thương mại cổ phần Hàng Hải Việt Nam (MSB)
1.2. DM
DM là tập hợp các thuật toán nhằm chiết xuất những thông tin có ích từ kho dữ liệu khổng lồ. DM được định nghĩa như một quá trình phát hiện mẫu trong dữ liệu, quá trình này có thể là tự động hay bán tự động, song phần nhiều là bán tự động. Các mẫu được phát hiện mang lại cho người sử dụng một lợi thế nào đó, thường là lợi thế về kinh tế. Theo đó, DM giống một quá trình tìm ra và mô tả mẫu dữ liệu. Dữ liệu là một tập hợp các sự vật hay sự kiện, đầu ra của quá trình DM thường là những dự báo của các sự vật hay sự kiện mới. Nó được áp dụng trong các cơ sở dữ liệu quan hệ, giao dịch hay trong kho dữ liệu phi cấu trúc mà điển hình là World Wide Web… Như vậy, mục đích của DM là tìm ra mẫu hoặc mô hình đang tồn tại trong các cơ sở dữ liệu nhưng vẫn còn bị khuất bởi số lượng dữ liệu khổng lồ. Quy trình DM gồm 6 giai đoạn:
Giai đoạn 1: Gom cụm dữ liệu (Gathering). Dữ liệu được gom từ trong một cơ sở dữ liệu, kho dữ liệu hay thanh chứa dữ liệu từ những nguồn cung ứng Web.
Giai đoạn 2: Trích lọc dữ liệu (Selection): Dữ liệu được lựa chọn và phân chia theo một số tiêu chuẩn nào đó, ví dụ chọn tất cả những người tuổi đời từ 25 - 35 và có trình độ đại học.
Giai đoạn 3: Làm sạch tiền xử lý và chuẩn bị trước các dữ liệu (Cleansing pre-processing, preparation): Đây là giai đoạn hay bị sao nhãng, nhưng thực tế nó là một bước rất quan trọng trong quá trình DM. Một số lỗi thường mắc phải trong giai đoạn này là dữ liệu không đầy đủ hoặc không thống nhất, thiếu chặt chẽ. Vì vậy dữ liệu thường chứa các giá trị vô nghĩa và không có khả năng kết nối. Ví dụ, sinh viên có tuổi là 200, đây là dữ liệu dư thừa, không có giá trị.
Giai đoạn 4: Chuyển đổi dữ liệu (Transformation): Dữ liệu được tổ chức để phù hợp hơn với mục đích của DM.
Giai đoạn 5: Phát hiện và trích mẫu dữ liệu (Pattern extraction and discovery): Là giai đoạn tư duy trong DM. Ở giai đoạn này, nhiều thuật toán khác nhau được sử dụng để trích ra các mẫu từ dữ liệu. Thuật toán thường dùng để trích mẫu dữ liệu là thuật toán phân loại dữ liệu, kết hợp dữ liệu, mô hình hóa dữ liệu tuần tự.
Giai đoạn 6: Đánh giá kết quả mẫu (Evaluation of result): Ở giai đoạn này, các mẫu dữ liệu được chiết xuất bởi phần mềm DM nhưng không phải mẫu dữ liệu nào cũng hữu ích, đôi khi nó còn bị sai lệch. Vì vậy cần phải đưa ra tiêu chuẩn đánh giá độ ưu tiên cho các mẫu dữ liệu để rút ra kết quả cần thiết.
1.3. Cây quyết định
Trong lĩnh vực học máy, cây quyết định là một kiểu mô hình dự báo, nghĩa là một ánh xạ từ các quan sát về một sự vật, hiện tượng tới kết luận về giá trị mục tiêu của sự vật, hiện tượng. Mỗi nút trong tương ứng với một biến; đường nối giữa nó với nút con của nó thể hiện giá trị cụ thể cho biến đó. Mỗi nút lá đại diện cho giá trị dự đoán của biến mục tiêu, cho trước giá trị dự đoán của các biến được biểu diễn bởi đường đi từ nút gốc tới nút lá đó. Kỹ thuật học máy dùng trong cây quyết định được gọi là học bằng cây quyết định, hay chỉ gọi với cái tên ngắn gọn là cây quyết định.
Cây quyết định là một phương tiện có tính mô tả dành cho việc tính toán các xác suất có điều kiện. Nó được mô tả là sự kết hợp của các kỹ thuật toán học và tính toán nhằm hỗ trợ việc mô tả, phân loại, tổng quát hóa một tập dữ liệu cho trước. Cây quyết định là sơ đồ phát triển có cấu trúc dạng cây, ví dụ như trong Hình 1:
Hình 1: Sơ đồ cây quyết định
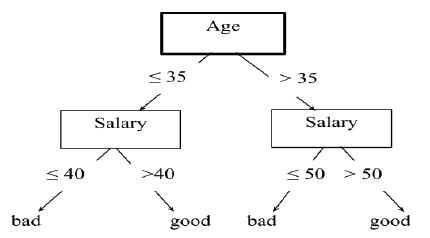
Nguồn: Tác giả tổng hợp
Trong đó:
- Gốc: Là nút trên cùng của cây.
- Nút trong: Biểu diễn một thuộc tính đơn.
- Nhánh: Là một đường đi trên cây, bắt đầu từ nút gốc đến nút lá.
- Nút lá: Biểu diễn tập giá trị cuối cùng của một nhánh.
- Độ cao, mức: Trong một cây, độ cao của đỉnh a là độ dài của đường đi dài nhất từ a đến một lá. Độ cao của gốc được gọi là độ cao của cây, mức của đỉnh a là độ dài của đường đi từ gốc đến a.
Cây quyết định có cấu trúc đơn giản, dễ hiểu và được xây dựng khá nhanh, từ cây quyết định có thể dễ dàng rút ra các luật (series of rules). Ví dụ, từ cây quyết định trong Hình 1, có thể rút ra được các luật sau:
IF (Age <= 35) AND (Salary <= 40) THEN class = bad
IF (Age <= 35) AND (Salary > 40) THEN class = good
IF (Age > 35) AND (Salary <= 50) THEN class = bad
IF (Age > 35) AND (Salary > 50) THEN class = good
Cách thức hoạt động của thuật toán cây quyết định thường thông qua thuật toán ID3 của Ross Quinlan. Đây là thuật toán xây dựng cây quyết định theo cách từ trên xuống. Bất kỳ thuộc tính nào cũng có thể phân vùng tập hợp các đối tượng thành những tập con tách rời với một giá trị chung. ID3 chọn một thuộc tính để kiểm tra tại nút hiện tại của cây và phân vùng tập hợp các đối tượng, thuật toán khi đó xây dựng theo cách đệ quy một cây con cho từng phân vùng. Việc này tiếp tục cho đến khi tập đối tượng của phân vùng đều nằm trong cùng một lớp, lớp đó trở thành nút lá của cây.
Thuật toán C4.5 của Ross Quinlan là một thuật toán cải tiến so với thuật toán ID3 do ID3 làm việc không hiệu quả với các thuộc tính có nhiều giá trị. Thuật toán C4.5 được sử dụng rộng rãi nhất trong thực tế cho đến nay. C4.5 là thuật toán phân lớp dữ liệu dựa trên cây quyết định rất hiệu quả và phổ biến trong những ứng dụng khai phá cơ sở dữ liệu có kích thước nhỏ. Kỹ thuật này cho phép giảm bớt kích thước tập luật và đơn giản hóa các luật mà độ chính xác so với nhánh tương ứng cây quyết định là tương đương. Công thức sử dụng trong thuật toán như sau:
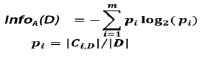
Trong đó:
pi: Xác suất để 1 phần tử bất kỳ trong D thuộc lớp Ci;
m: Số lớp;
InfoA(D): Lượng thông tin cần để phân loại một phần tử trong D dựa trên thuộc tính A. Thuộc tính A dùng phân tách D thành v phân hoạch (D1, D2... Dv). Mỗi phân hoạch Dj gồm |Dj| phần tử trong D. Lượng thông tin này sẽ cho biết mức độ trùng lặp giữa các phân hoạch, nghĩa là một phân hoạch chứa các phần tử từ một lớp hay nhiều lớp khác nhau.
Độ đo Information Gain: Là độ sai biệt giữa trị thông tin Info(D) ban đầu (trước phân hoạch) với trị thông tin mới InfoA(D) (sau phân hoạch với A).
Gain(A) = Info(D) - InfoA(D) Information Gain được sử dụng làm tiêu chuẩn để lựa chọn thuộc tính khi phân lớp. Thuộc tính được chọn là thuộc tính có Gain đạt giá trị lớn nhất.
Để giải quyết vấn đề một thuộc tính được dùng tạo ra rất nhiều phân hoạch (thậm chí mỗi phân hoạch chỉ gồm 1 phân tử), thuật toán C4.5 đã đưa ra các đại lượng GainRatio và SplitInfo, chúng được xác định theo công thức:
Giá trị SplitInfo là đại lượng đánh giá thông tin tiềm năng thu thập được khi phân chia tập D thành v tập con. GainRatio là tiêu chuẩn để đánh giá việc lựa chọn thuộc tính phân loại. Thuộc tính được lựa chọn là thuộc tính có GainRatio đạt giá trị lớn nhất.
Để đánh giá hiệu suất của một cây quyết định, người ta thường sử dụng một tập ví dụ tách rời, tập này khác với tập dữ liệu huấn luyện để đánh giá khả năng phân loại của cây trên các ví dụ của tập này. Tập dữ liệu này gọi là tập kiểm tra. Thông thường, tập dữ liệu sẵn có sẽ được chia thành hai tập: Tập rèn luyện thường chiếm 2/3 số ví dụ và tập kiểm tra chiếm 1/3. Ma trận dưới đây được sử dụng để đánh giá hiệu quả của việc phân lớp với cây quyết định nói chung, C4.5 nói riêng. (Bảng 2)
Bảng 2: Ma trận xác định độ chính xác
của bộ phân lớp
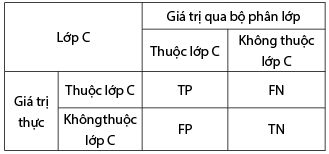
Nguồn: Tổng hợp của tác giả
Trong đó:
- TP: Là số mẫu thuộc lớp C được phân lớp đúng.
- TN: Là số mẫu không thuộc lớp C được phân lớp đúng.
- FP: Là số mẫu thuộc lớp C mà bộ phân lớp sai.
- FN: Là số mẫu không thuộc lớp C mà bộ phân lớp sai.
Từ đó, các độ đo đánh giá quá trình phân lớp được tính như sau:

2. Giải pháp chấm điểm tín dụng dựa trên kỹ thuật cây quyết định C4.5
Nguyên lý hoạt động và các độ đo quan trọng của cây quyết định C4.5 đã được giới thiệu trong các phần trước, trong phần tiếp theo, bài viết sẽ trình bày về việc ứng dụng cây quyết định này để xây dựng mô hình dự báo một khách hàng có được vay vốn hay không dựa trên điểm tín dụng của họ với ví dụ minh họa là bộ dữ liệu khách hàng từ MSB. Một tập cơ sở dữ liệu ban đầu của khách hàng liên quan đến khoản vay với các giá trị dữ liệu đã biết về thuộc tính như: Tuổi, trình độ học vấn, tình trạng hôn nhân, số người phụ thuộc, tính chất công việc, thu nhập hằng tháng.
Đầu vào: Bộ dữ liệu về thông tin khách hàng.
Đầu ra: Các luật về xếp hạng tín dụng khách hàng cá nhân tại ngân hàng.
Công cụ sử dụng: Phần mềm Weka.
Dữ liệu được sử dụng để xây dựng bài toán là một tập hợp các thông tin về khách hàng cá nhân xin cấp tín dụng tại MSB. Dữ liệu này bao gồm 866 bản ghi, được lưu trữ dưới dạng file excel và được chuyển thành file csv như Bảng 3.
Bảng 3: Dữ liệu thông tin khách hàng xin cấp tín dụng tại MSB
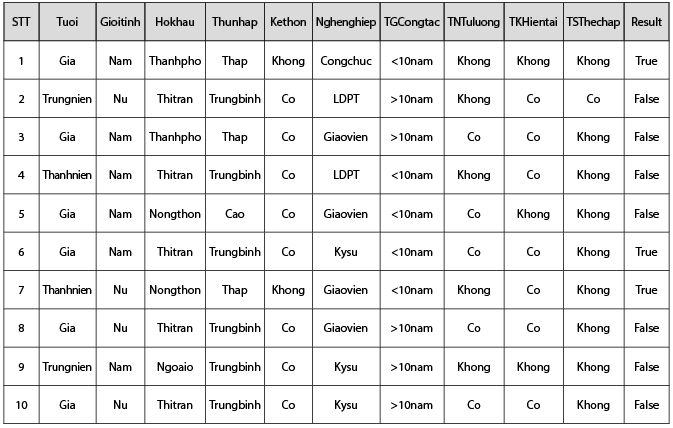
Nguồn: Tác giả tổng hợp từ bộ dữ liệu
Bộ dữ liệu gồm có 17 thuộc tính khác nhau, mỗi thuộc tính đều có giá trị hữu hạn. Tên các thuộc tính và tập giá trị của nó được trình bày trong Bảng 4.
Bảng 4: Các thuộc tính và tập giá trị của nó
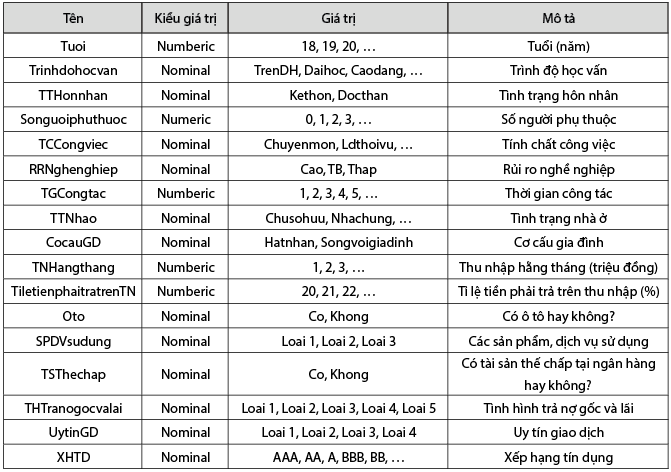
Nguồn: Tác giả tổng hợp từ bộ dữ liệu
- Sản phẩm, dịch vụ sử dụng:
Loại 1: Tiền gửi và các dịch vụ khác.
Loại 2: Chỉ sử dụng dịch vụ thanh toán.
Loại 3: Không sử dụng.
- Tình hình trả nợ gốc và lãi:
Loại 1: Luôn trả nợ đúng hạn.
Loại 2: Đã bị gia hạn nợ, hiện trả nợ tốt.
Loại 3: Đã có nợ quá hạn hoặc khách hàng mới.
Loại 4: Đã có nợ quá hạn, khách hàng trả nợ không ổn định.
Loại 5: Hiện đang có nợ quá hạn.
- Uy tín giao dịch:
Loại 1: Có giao dịch vào, ra đều đặn hoặc trả nợ đầy đủ.
Loại 2: Khách hàng mới, chưa cấp hạn mức.
Loại 3: Từ 2 đến 3 tháng không có giao dịch tiền vào và (hoặc) phát sinh nợ loại 2.
Loại 4: Trên 3 tháng không có giao dịch tiền vào và (hoặc) phát sinh nợ loại 3, 4, 5.
Trong quá trình DM, công việc tiền xử lý dữ liệu trước khi đưa vào mô hình là rất cần thiết. Bước này cho biết dữ liệu qua thu thập ban đầu có thể được áp dụng thích hợp với các mô hình DM cụ thể. Các công việc bao gồm:
- Filtering Attributes: Chọn các thuộc tính phù hợp với mô hình.
- Filtering Sample: Lọc các mẫu dữ liệu cho mô hình.
- Transformation: Chuyển đổi kiểu dữ liệu cho phù hợp.
- Discretization: Rời rạc hóa dữ liệu.
Cụ thể đối với thuộc tính được mã hóa mô tả tại Bảng 5, 6, 7, 8, 9.
Bảng 5: Gán nhãn cho thuộc tính “tuổi”

Nguồn: Tác giả tổng hợp từ bộ dữ liệu
Bảng 6: Gán nhãn cho thuộc tính
“số người phụ thuộc”

Nguồn: Tác giả tổng hợp từ bộ dữ liệu
Bảng 7: Gán nhãn cho thuộc tính
“thời gian công tác”
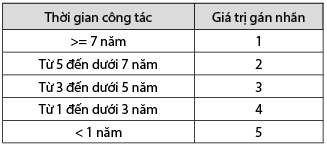
Nguồn: Tác giả tổng hợp từ bộ dữ liệu
Bảng 8: Gán nhãn cho thuộc tính
“thu nhập hằng tháng”
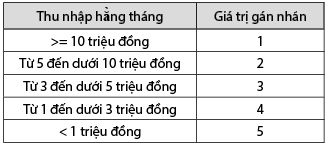
Nguồn: Tác giả tổng hợp từ bộ dữ liệu
Bảng 9: Gán nhãn cho thuộc tính
“tỉ lệ số tiền phải trả trên thu nhập”
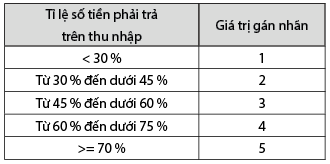
Nguồn: Tác giả tổng hợp từ bộ dữ liệu
3. Thực nghiệm
Sau khi đã thực hiện qua bước tiền xử lý dữ liệu, tác giả tiến hành phân loại dữ liệu bằng thuật toán C4.5. Trước khi tiến hành phân loại, tác giả chọn chế độ kiểm thử để xây dựng tập kiểm thử và tập huấn luyện. Weka hỗ trợ 4 chế độ kiểm thử:
- Use training set: Sử dụng chính tập training data để tiến hành kiểm thử.
- Supplied test set: Sử dụng tập dữ liệu khác để tiến hành kiểm thử.
- Cross-validation: Chia dữ liệu thành nhiều phần để thực hiện thành nhiều lần đánh giá kết quả.
- Percentage split: Chia dữ liệu thành hai phần theo tỉ lệ %, một phần dùng để xây dựng mô hình, một phần dành cho kiểm thử.
Sử dụng chế độ kiểm thử Use training set thu được kết quả như Hình 2.
Hình 2: Kết quả thuật toán dưới dạng Text
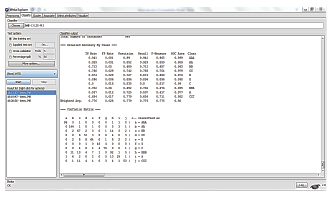
Nguồn: Tác giả tổng hợp từ phần mềm Weka
Kết quả thu được sau quá trình huấn luyện là tập các luật thu được dạng mô hình cây như sau:
TGCongtac = 2
| UytinGD = Loai 1
| | Songuoiphuthuoc = 1
| | | Trinhdohocvan = TrenDH: AA (1.0)
| | | Trinhdohocvan = Daihoc
| | | | SPDVsudung = Loai 1: AAA (3.0)
| | | | SPDVsudung = Loai 2: AA (2.0)
| | | Trinhdohocvan = Trunghoc: AA (0.0)
| | | Trinhdohocvan = Duoitrunghoc: BBB (2.0)
| | | Trinhdohocvan = Caodang: AA (2.0)
| | Songuoiphuthuoc = 2: AA (11.0)
| | Songuoiphuthuoc = 3: BBB (1.0)
| | Songuoiphuthuoc = 4: AA (0.0)
| | Songuoiphuthuoc = 5: A (1.0)
…
Căn cứ vào các luật được sinh ra như trên, chúng ta có thể diễn giải các luật đó cụ thể hơn từ cây quyết định:
- Luật 1: IF (TGCongtac = 1) AND (UytinGD = Loai 1) AND (SPDVsudung = Loai 1) AND (TTNhao = Chusohuu) THEN (XHTD = AAA).
- Luật 2: IF (TGCongtac = 1) AND (UytinGD = Loai 1) AND (SPDVsudung = Loai 1) AND (TTNhao = Thue) THEN (XHTD = AA).
- Luật 3: IF (TGCongtac = 1) AND (UytinGD = Loai 1) AND (SPDVsudung = Loai 2) AND (Songuoiphuthuoc = 1) AND (Tuoi = 1) THEN (XHTD = AA).
- Luật 4: IF (TGCongtac = 1) AND (UytinGD = Loai 1) AND (SPDVsudung = Loai 2) AND (Songuoiphuthuoc = 1) AND (Tuoi = 2) THEN (XHTD = BBB).
- Luật 5: IF (TGCongtac = 1) AND (UytinGD = Loai 1) AND (SPDVsudung = Loai 2) AND (Songuoiphuthuoc = 1) AND (Tuoi = 3) AND (Trinhdohocvan = Daihoc THEN (XHTD = AA).
- Luật 6: IF (TGCongtac = 2) AND (UytinGD = Loai 1) AND (Songuoiphuthuoc = 1) AND (Trinhdohocvan = TrenDH) THEN (XHTD = AA).
- Luật 7: IF (TGCongtac = 2) AND (UytinGD = Loai 1) AND (Songuoiphuthuoc = 1) AND (Trinhdohocvan = Daihoc) AND (SPDVsudung = Loai 1) THEN (XHTD = AAA).
- Luật 8: IF (TGCongtac = 2) AND (UytinGD = Loai 4) AND (SPDVsudung = Loai 1) AND (Oto = Khong) AND (TSThechap = Khong) THEN (XHTD = CCC).
Bài toán xây dựng cây quyết định xếp hạng tín dụng được thử nghiệm trên phần mềm Weka với bộ số liệu của MSB thu được kết quả tương đối tốt. Dựa vào kết quả thực nghiệm, thu được các thông tin như Hình 3.
Hình 3: Kết quả sau khi thực hiện trên phần mềm Weka
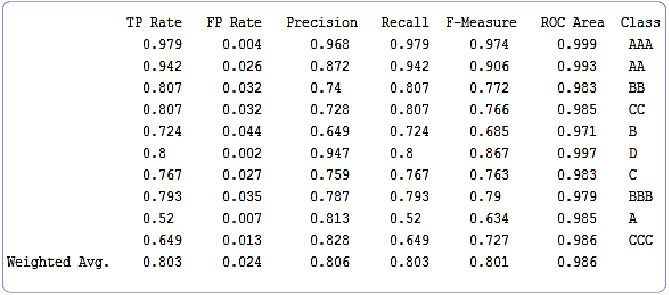
Nguồn: Tác giả tổng hợp từ phần mềm Weka
Từ Hình 3, ta thấy lớp “AAA”có độ chính xác cao nhất với tỉ lệ các mẫu được phân lớp đúng đạt 97,9%, chỉ có 0,4% mẫu bị phân lớp sai. Tỉ lệ các mẫu thuộc lớp “AAA” được phân loại đúng lần lượt chiếm 96,8%, 97,9% trên tổng số các mẫu được phân loại vào lớp "AAA" và trên tổng số các mẫu có giá trị thực thuộc lớp này. Giá trị F-Measure và ROC Area càng tiến gần về 1 có nghĩa mô hình càng tốt. Tương tự với các lớp còn lại.
Với mô hình cây quyết định, kết quả được mô phỏng phân loại một cách trực quan, dễ hiểu đối với người sử dụng, có thể rút ra các luật một cách nhanh chóng, dễ dàng dự đoán trước khả năng của khách hàng, từ đó đưa ra những quyết định phù hợp hơn.
4. Kết luận và hướng phát triển
Các ngân hàng thương mại thường xuyên phải đưa ra các quyết định liên quan đến quá trình cho vay của mình với mục tiêu giảm thiểu tối đa rủi ro cho vay. Với dự đoán đã thu được, nhà quản trị ngân hàng có thể sẽ dễ dàng ra quyết định tùy vào tình huống thực tế. Tuy nhiên, với bộ dữ liệu thu thập được có kích thước tương đối nhỏ, kết quả phân loại khi sử dụng cây quyết định đối với các trường hợp khác có thể chưa cao. Các luật cung cấp thêm thông tin, gợi ý trong quá trình xếp hạng tín dụng nhưng không dựa vào hoàn toàn. Tùy vào từng trường hợp, từng khách hàng cụ thể mà ngân hàng có thể áp dụng một cách linh hoạt. Như vậy, với những kết quả đã rút ra được, có thể khẳng định rằng, phương pháp cây quyết định áp dụng trong xếp hạng tín dụng là một hướng tiếp cận tiềm năng. Do đó, nhóm tác giả đề xuất một số vấn đề cần nghiên cứu, phát triển để các ngân hàng có thể áp dụng mô hình cây quyết định như sau:
Thứ nhất, cần bổ sung thêm dữ liệu cho tập huấn luyện để mô hình cây quyết định có độ tin cậy cao hơn và hoạt động hiệu quả hơn. Đặc biệt là việc tổng hợp các nguồn dữ liệu từ các ngân hàng thương mại khác nhau.
Thứ hai, tiếp tục phát triển, hoàn thiện theo hướng DM trở thành phần mềm trong tín dụng tiêu dùng nhằm hỗ trợ cán bộ tín dụng đưa ra quyết định cho khách hàng vay và quản trị rủi ro tín dụng hiệu quả.
Thứ ba, tiếp tục nghiên cứu các thuật toán về DM và học máy nhằm áp dụng nhiều hơn nữa các kỹ thuật này trong lĩnh vực tài chính, ngân hàng.
Thứ tư, đẩy mạnh hợp tác nghiên cứu giữa trường đại học với ngân hàng thương mại để ứng dụng các nghiên cứu từ trường đại học vào thực tế, đồng thời, sử dụng được nguồn dữ liệu từ ngân hàng thương mại trong việc nghiên cứu.
Tài liệu tham khảo:
1. Bhatia, S., Sharma, P., Burman, R., Hazari, S., & Hande, R, (2017), Credit scoring using machine learning techniques., International Journal of Computer Applications, 161(11), pages 1-4.
2. Ian H. Witten, Eibe Frank, and Marker Hall, (2011), “Data Mining- Practical Machine Learning Tools and Techniques”, Morgan Kaufmann.
3. Leo, M., Sharma, S., & Maddulety, K., (2019), Machine learning in banking risk managemen, t: A literature review. Risks, 7(1), 29.
4. M Madhavi, M V R Srivatsava, 92023), “Fraud Detection in Banking”, International Journal of Engineering and Advanced Technology, Volume 3, Issue 1, pages 322-358.
5. M. Al-Shabi, 92019), Credit card fraud detection using autoencoder model in unbalanced datasets, J. Adv. Math. Comput. Sci, 33, pages 1-16.
6. Meenakshi, D., & Janani, (2019), Credit Card Fraud Detection Using Random Forest., International Research Journal of Engineering and Technology (IRJET), 6.
7. S. Ghosh, DL Reilly, (2004), Credit card fraud detection with a neural-network, Proceedings of the Twenty-Seventh Hawaii International Conference on. Vol. 3. IEEE, 1994.
ThS. Nguyễn Dương Hùng; ThS. Ngô Thùy Linh
Khoa Công nghệ thông tin và Kinh tế số, Học viện Ngân hàng
https://tapchinganhang.gov.vn






















