Thẻ tín dụng ngày càng trở nên phổ biến, điều đó kéo theo sự phát triển nhiều hành vi gian lận trong các giao dịch của loại hình thanh toán này...
Tóm tắt:
Thẻ tín dụng ngày càng trở nên phổ biến, điều đó kéo theo sự phát triển nhiều hành vi gian lận trong các giao dịch của loại hình thanh toán này. Các ngân hàng cần xây dựng hệ thống nhận diện và cảnh báo những giao dịch gian lận nhằm hạn chế thất thoát tài chính. Trong bài viết này, tác giả xây dựng mô hình phán đoán giao dịch gian lận dựa trên bốn thuật toán học máy không giám sát: One-class Support Vector Machine (One-class SVM), K-means, rừng cô lập (Isolation forest) và Local outlier factor (LOF). Từ đó đưa ra so sánh, đánh giá về thời gian thực hiện và hiệu quả của mỗi thuật toán.
Từ khóa: Gian lận thẻ tín dụng, học máy không giám sát.
1. Giới thiệu
Thẻ tín dụng ngày càng trở nên phổ biến trong các hình thức giao dịch online và offline. Đi cùng với sự phát triển và thịnh hành loại hình thanh toán này là các loại tội phạm lừa đảo sử dụng công nghệ cao. Nhận diện những giao dịch lừa đảo liên quan tới thanh toán thẻ tín dụng là một chủ đề nghiên cứu đang được quan tâm trong lĩnh vực trí tuệ nhân tạo và khoa học dữ liệu. Đồng thời, hoạt động này cũng đóng vai trò quan trọng đối với các ngân hàng, giúp các ngân hàng giảm thiểu các thất thoát do những lừa đảo trong các giao dịch. Nhiều kỹ thuật đã được đưa ra và thu được kết quả khả quan, tuy nhiên, độ chính xác và tốc độ xử lý vẫn là một trong những thách thức lớn nhất, bởi dữ liệu thường phân bố rất lệch và thay đổi theo thời gian. Các kỹ thuật học máy có giám sát và không có giám sát đã được áp dụng trong phát hiện lừa đảo trong các giao dịch thẻ tín dụng.
Học máy có giám sát hay còn gọi là học có thầy, là thuật toán dự đoán nhãn/đầu ra của một dữ liệu mới dựa trên tập dữ liệu huấn luyện mà trong đó mỗi mẫu dữ liệu đều đã được gán nhãn. Khi đó, thông qua một quá trình huấn luyện, một mô hình sẽ được xây dựng để cho ra các dự đoán và khi các dự đoán bị sai thì mô hình này sẽ được tinh chỉnh lại. Việc huấn luyện sẽ tiếp tục cho đến khi mô hình đạt được mức độ chính xác mong muốn trên dữ liệu huấn luyện.
Trái với học máy có giám sát, học không giám sát là thuật toán dự đoán nhãn của một dữ liệu mới dựa trên tập dữ liệu huấn luyện mà trong đó, tất cả các mẫu dữ liệu đều chưa được gán nhãn hay nói cách khác là ta không biết câu trả lời chính xác cho mỗi dữ liệu đầu vào. Khi đó, mục tiêu của thuật toán không giám sát không phải là tìm đầu ra chính xác mà sẽ hướng tới việc tìm ra cấu trúc hoặc sự liên hệ trong dữ liệu để thực hiện một công việc nào đó.
Mô hình học máy có giám sát thường thực hiện rất tốt với bộ dữ liệu cân bằng (số lượng dữ liệu giữa các lớp tương đương nhau). Tuy nhiên, đối với bộ dữ liệu không cân bằng, tức là có sự chênh lệch rất lớn về mặt số lượng giữa các lớp, sẽ mất rất nhiều thời gian để phân cụm những giao dịch bình thường, trong khi phát hiện ra những dữ liệu ngoại lệ mới là vấn đề trọng tâm. Trong khi đó, các thuật toán học máy không giám sát có thể xử lý tốt trong trường hợp dữ liệu mất cân bằng hoặc không đủ nhãn. Một ưu điểm khác của học máy không giám sát là thời gian cập nhật mô hình ngắn, do đó phù hợp để sử dụng trong phát hiện các gian lận trong giao dịch. Chính vì vậy, trong bài viết này, tác giả lựa chọn bốn thuật toán học máy không có giám sát: One-class SVM, K-means, Isolation forest và LOF để đánh giá hiệu quả của chúng trong phát hiện các lừa đảo trong giao dịch thẻ tín dụng dựa trên bộ dữ liệu về giao dịch thẻ tín dụng của trang Kaggle (một trong những trang web chuyên về khoa học dữ liệu). Đóng góp chính của bài viết là đưa ra sự so sánh các thuật toán học máy bằng cách đưa ra các độ đo về hiệu quả thực hiện trên cùng một bộ dữ liệu.
2. Một số thuật toán học máy không có giám sát
Thuật toán One-class SVM
Đây là một thuật toán dùng để phân chia dữ liệu thành các nhóm riêng biệt bằng cách xây dựng một siêu phẳng (hyperplane). Về mặt ý tưởng, One-class SVM sử dụng thuật toán để ánh xạ tập dữ liệu ban đầu vào không gian nhiều chiều hơn. Khi đã ánh xạ sang không gian nhiều chiều, One-class SVM sẽ xem xét và chọn ra siêu phẳng phù hợp nhất để phân lớp tập dữ liệu đó.
Scholkopf giới thiệu thuật toán One-class SVM (OC-SVM) vào năm 2001. Đây là thuật toán mở rộng của SVM. Về cơ bản, thuật toán thực hiện tách tất cả các điểm dữ liệu khỏi điểm gốc (trong không gian đặc trưng F) và tối đa khoảng cách từ siêu phẳng này đến điểm gốc. Việc phán đoán ngoại lệ dựa vào một hàm nhị phân. Hàm này thu thập các vùng trong không gian đầu vào nơi mật độ xác suất của dữ liệu tồn tại và trả về giá trị +1 nếu điểm nằm trong vùng thu thập các điểm dữ liệu huấn luyện và -1 đối với các vùng khác.
Thuật toán K-means
K-means là thuật toán đơn giản và phổ biến nhất trong số các thuật toán học máy không giám sát. Mục đích của thuật toán là phân chia các đối tượng đã cho vào các cụm khác nhau, trong đó số lượng cụm được cho trước. Công việc phân cụm được xác lập dựa trên nguyên lý: Các điểm dữ liệu trong cùng một cụm thì phải có cùng một số tính chất nhất định. Tức là giữa các điểm trong cùng một cụm phải có sự liên quan lẫn nhau. Đối với máy tính thì các điểm trong một cụm sẽ là các điểm dữ liệu gần nhau.
Thuật toán Isolation forest
Thuật toán này được đề xuất bởi Fei Tony Liu, Kai Ming Ting and Zhi-Hua Zhou vào năm 2006. Hầu hết các kỹ thuật dùng để phát hiện dị thường thường dựa trên định nghĩa “thế nào là bình thường”. Từ đó, những gì không nằm trong bộ bình thường thì được coi là bộ dị thường. Trong khi đó, thuật toán Isolation forest lại dùng cách tiếp cận khác: Thay vì xây dựng mô hình nhận diện các bộ bình thường, nó tìm cách cô lập các bộ dị thường trong tập dữ liệu. Ưu điểm của cách tiếp cận này là tốc độ xử lý nhanh và đòi hỏi ít bộ nhớ.
Thuật toán LOF
LOF được Markus M. Breunig, Hans-Peter Kriegel, Raymond T. Ng và Jorg Sander giới thiệu vào năm 2000. Mục đích của thuật toán là tìm các điểm dị thường bằng cách đo độ lệch cục bộ của một điểm dữ liệu đối với các điểm lân cận nó. LOF dùng chung một số kỹ thuật giống thuật toán DBSCAN và OPTICS, chẳng hạn như khái niệm khoảng cách cốt lõi (core distance) và khoảng cách tiếp cận (reachability distance).
3. Dữ liệu và phương pháp đánh giá
Phương pháp thực hiện
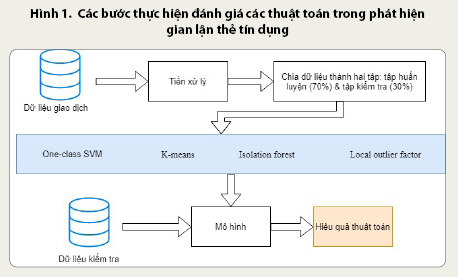
Để đánh giá hiệu quả của các thuật toán trong phát hiện các giao dịch thẻ tín dụng, tác giả đề xuất các bước thực hiện như sau:
Bước 1: Thực hiện tiền xử lý dữ liệu;
Bước 2: Tách dữ liệu giao dịch thành hai tập: huấn luyện và kiểm tra;
Bước 3: Thực hiện các thuật toán với tập dữ liệu huấn luyện để đưa ra mô hình phán đoán gian lận;
Bước 4: Sử dụng tập dữ liệu kiểm tra để tìm độ chính xác của các mô hình. (Hình 1)
Dữ liệu
Trong bài viết này, dữ liệu về các giao dịch thẻ tín dụng trong hai ngày vào tháng 9/2013 của những khách hàng khu vực châu Âu được sử dụng để đánh giá các thuật toán. Tập dữ liệu được khai thác trên trang Kaggle.
Bộ dữ liệu bao gồm 31 trường, bao gồm: Các trường được đặt tên từ V1 đến V28 nhằm che giấu đi những thông tin nhạy cảm, cột Time, Amount và Class (cột Class thể hiện giao dịch đó hợp lệ hay gian lận).
Bộ dữ liệu phân bố rất lệch, có 492 giao dịch được ghi nhận là gian lận (chiếm 0,172%) trong tổng số 284.807 giao dịch. (Hình 2)

4. Các độ đo
Có nhiều độ đo khác nhau để đánh giá hiệu quả của một thuật toán. Các độ đo này dựa trên số lượng giao dịch phát hiện đúng hoặc sai: False Positive (FP), False Negative (FN), True Positive (TP) và True Nagative (TN).
- True Positive: số lượng các giao dịch gian lận được phân loại chính xác vào lớp gian lận.
- True Negative: số lượng giao dịch hợp lệ được phát hiện đúng.
- False Positive: số lượng các giao dịch không phải là gian lận bị phân loại nhầm vào lớp gian lận.
- False Negative: số lượng giao dịch gian lận bị phân loại nhầm vào giao dịch hợp lệ.
Accuracy là tỷ lệ giữa số điểm được dự đoán đúng và tổng số điểm trong tập dữ liệu kiểm thử.

Precision
Precision là tỷ lệ giao dịch gian lận thật sự trong tổng số các giao dịch được phán đoán là gian lận.
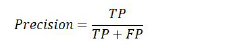
Recall hay còn gọi là độ nhạy
Recall là tỷ lệ những giao dịch được phán đoán đúng là gian lận trong tổng số các gian lận thực tế.

F1-score
Đối với những tập dữ liệu không cân bằng (có sự chênh lệch rất lớn giữa số lượng giao dịch hợp lệ và giao dịch gian lận) thì Accuracry, Precision hay Recall không phản ánh được độ chính xác và hiệu quả của thuật toán. Do vậy, cần sử dụng các độ đo mới, một trong số đó là F1-score.
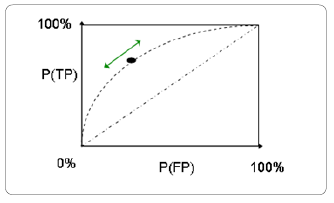
Receiver Operating Characteristic (ROC)
Để tránh chủ quan khi chỉ lựa chọn một ngưỡng để đánh giá mô hình, có một cách là duyệt qua hết tất cả các ngưỡng có thể được và quan sát ảnh hưởng lên các tỷ lệ dự báo TPR và FPR. Khi đó, sẽ dựng được đường cong ROC chứa tất cả các điểm TPR và FPR. (Hình 3)
Hình 3. Minh họa độ đo ROC
Đối với bộ dữ liệu lệch, độ chính xác không đủ để đánh giá tính hiệu quả của thuật toán. Do vậy, trong nội dung bài viết này, tác giả sử dụng độ đo F1-score và ROC.
5. Đánh giá
Sau khi thực hiện các thuật toán để xây dựng mô hình và dự đoán trên cùng một nền tảng phần cứng, ta thấy được sự khác biệt rất lớn về thời gian thực hiện giữa các thuật toán. (Hình 4) One-class SVM cần nhiều thời gian để huấn luyện nhất, trong khi đó thuật toán Isolation forest tốn ít thời gian huấn luyện nhất. Thời gian dự đoán của K-means ít nhất trong khi On-class SVM tốn rất nhiều thời gian để đưa ra kết quả dự đoán.
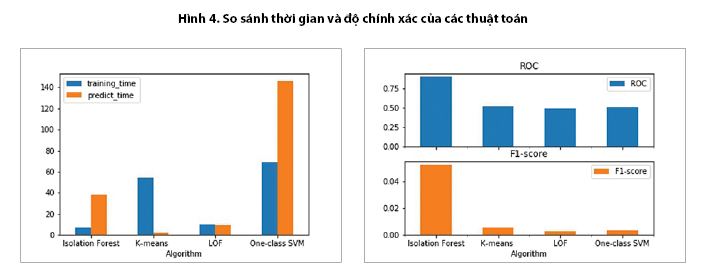
Xét về hiệu quả của thuật toán, Isolation forest là thuật toán có hiệu quả tốt nhất với ROC = 90,2% và F1-score = 5,2%.
6. Đề xuất hệ thống kiểm tra gian lận trong giao dịch thẻ tín dụng
Với thời gian dự đoán và tính chính xác đã nêu ở phần trên, các thuật toán học máy không giám sát có thể ứng dụng vào xây dựng hệ thống giám sát gian lận trong giao dịch thẻ tín dụng nhằm giảm thiểu công sức con người. Tác giả đề xuất hệ thống nhận diện gian lận có hoạt động như trong Hình 5.

Trong hệ thống này, dữ liệu giao dịch lịch sử được đưa vào kho để làm tập dữ liệu huấn luyện. Từ thuật toán học máy được lựa chọn và tập dữ liệu huấn luyện, hệ thống đưa ra mô hình nhận diện gian lận. Mỗi khi có phát sinh giao dịch mới, hệ thống căn cứ vào dữ liệu giao dịch và dùng mô hình nhận diện gian lận để phán đoán, sau đó module ra quyết định sẽ xác định giao dịch là hợp lệ hay gian lận.
Để cải thiện độ chính xác của hệ thống, dữ liệu giao dịch được cập nhật định kỳ vào kho để huấn luyện lại mô hình.
7. Kết luận
Trong phát hiện gian lận, các thuật toán học máy không giám sát tiến hành mô hình sự phân bố dữ liệu vào một lớp và nhận diện xem dữ liệu kiểm thử (dữ liệu về giao dịch) có thuộc vào lớp này hay không. Theo kết quả thực nghiệm, thời gian xây dựng mô hình và phán đoán gian lận của các thuật toán nêu trên ngắn và độ chính xác khá cao.
Trong số bốn thuật toán học máy đã thực nghiệm thì Isolation forest có độ chính xác cao nhất (với ROC = 90,2%). Tuy nhiên, tỷ lệ phát hiện gian lận này chưa phải là tỷ lệ tốt nhất, do vậy cần phải làm giàu dữ liệu huấn luyện và có những cải tiến để đạt kết quả cao hơn nữa.
Tài liệu tham khảo:
1. A. A. P. S. Benson Edwin Raj, “Analysis on Credit Card Fraud Detection Methods,” in International Conference on Computer, Communication and Electrical Technology - ICCCET2011, 2011.
2. A. C. Bahnsen, A. Stojanovic, D. Aouada and B. Ottersten, “Cost Sensitive Credit Card Fraud Detection Using Bayes Minimum Risk,” in 12th International Conference on Machine Learning and Applications, 2013.
3. D. C. Y. T. L. Z. Kang Fu, “Credit Card Fraud Detection Using Convolutional Neural Networks,” in International Conference on Neural Information Processing, 2016.
4. K. Randhawa, C. K. Loo, M. Seera, C. P. Lim and A. K. Nandi, “Credit Card Fraud Detection Using AdaBoost and Majority Voting,” IEEE Access, vol. 6, pp. 14277 - 14284, 2018.
5. S. K. N. J. Rehan Akbani, “Applying Support Vector Machines to Imbalanced Datasets,” in European Conference on Machine Learning, 2004.
6. T. chlegl, P. Seebock and Waldstein, “discovery, Unsupervised anomaly detection with generative adversarial networks to guide marker,” in International Conference on Information Processing in Medical Imaging, 2017.
7. V. VN, Statistical Learning Theory, Vapnik VN, 1998.
8. J. B. MacQueen, “ Some Methods for classification and Analysis of Multivariate Observations,” Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability, 2009.
9. M. G. S. A. Mennatallah Amer, “Enhancing one-class support vector machines for unsupervised anomaly detection,” in ODD ‘13: Proceedings of the ACM SIGKDD Workshop on Outlier Detection and Description, 2013.
10. F. T. Liu, K. M. Ting and Z.-H. Zhou, “Isolation Forest,” in Eighth IEEE International Conference on Data Mining, 2008.
11. M. M. Breunig, H.-P. Kriegel, R. T. Ng and J. Sander, “LOF: Identifying Density-based Local Outliers,” in Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000.
12. M. L. G. -. ULB, “Credit card fraud detection,” 2018. [Online]. Available: https://www.kaggle.com/mlg-ulb/creditcardfraud.
13. C. M. Bishop, Pattern recognition and machine learning, Springer, 2006.
14. D. M. Powers, “ROC-ConCert: ROC-Based Measurement of Consistency and Certainty,” Spring Congress on Engineering and Technology (SCET), 2012.
15. Fei Tony Liu, Kai Ming Ting, Zhi-Hua Zhou, “Isolation forest,” in In Data Mining, 2008. ICDM’08. Eighth IEEE International Conference.
16. P. J. S.-T. J. S. A. W. R. Sch¨olkopf B, “Estimating the Support of a High-Dimensional Distribution,” Neural Computation, 2001.
17. S. A. Sch¨olkopf B, Learning with Kernels, Cambridge: MIT Press, 2002.
18. G. I. V. V. Boser BE, “A training algorithm for optimal margin classifiers,” Proceedings of the Fifth Annual Workshop on Computational Learning Theory, 1992.
19. V. Chandola, A. Banerjee and K. Kumar, “Anomaly Detection: A Survey,” in ACM Computing Surveys, 2009.
20. Fei Tony Liu, Kai Ming Ting, Zhi-Hua Zhou, “Isolation-Based Anomaly Detection,” in ACM Transactions on Knowledge Discovery from Data, 2012.
21. J. P. J. S.-T. A. J. S. R. W. B. Scholkopf, “Estimating the support of a high-dimentional distribution,” Neural Computation, 2001.
ThS. Cao Thị Nhâm
Đại học Kinh tế - Đại học Đà Nẵng
https://tapchinganhang.gov.vn























