Trong thời đại của kỷ nguyên chuyển đổi số và cuộc Cách mạng công nghiệp lần thứ tư (CMCN 4.0), việc các ngân hàng ứng dụng trí tuệ nhân tạo (Artificial Intelligence - AI) đã trở thành một xu hướng tất yếu. Bài toán số hóa các văn bản tự động từ dạng bản cứng (trên giấy) thành các dữ liệu được lưu trữ dưới dạng số không những giúp ngân hàng tránh mất mát thông tin, đồng thời, người sử dụng có thể dễ dàng tìm kiếm và truy xuất thông tin. Bài viết đề xuất cách giải quyết khâu quan trọng nhất trong việc số hóa tài liệu, đó là nhận dạng chữ viết trong hình ảnh (Optical Character Recognition - OCR). Trên thực tế, các dạng chữ viết trên văn bản rất đa dạng và nhiều kiểu từ chữ in hoa, chữ in thường và cả chữ viết tay, thậm chí lại có nhiều kiểu định dạng như in đậm, in nghiêng... gây tốn kém thời gian của nhân viên để thao tác các hoạt động truyền thống như kiểm tra, lưu trữ các biên lai, chứng minh thư... Từ nhu cầu thực tế đó, việc sử dụng AI để chuyển hóa chữ viết từ hình ảnh của văn bản thành các văn bản số hóa là một giải pháp cần thiết. Quy trình này sẽ bao gồm các bước: Chuyển dữ liệu gốc ban đầu về dạng ảnh; nhận diện thông tin từ các ảnh chụp chuyển thể thành các văn bản, hoặc bóc tách thành các trường thông tin có ý nghĩa. Để giải quyết bài toán nhận dạng chữ viết từ hình ảnh của văn bản, các mô hình phát hiện chữ (text detection) và nhận diện chữ (text recognition) bằng các mạng thần kinh tích chập (Convolutional Neural Network - CNN), mạng thần kinh hồi quy (Recurrent Neural Network - RNN), cơ chế chú ý (Attention Mechanism) được sử dụng. Kết quả thử nghiệm giải pháp đề xuất trên bộ dữ liệu chữ viết tay của người Việt đạt độ chính xác cao, có thể ứng dụng trong thực tiễn.
I. Giới thiệu
Bài toán nhận diện chữ trong ảnh hay kỹ thuật OCR đã có từ những năm 90 của thế kỷ trước. Lần đầu tiên OCR bắt đầu được mọi người biết đến rộng rãi vào năm 1913 khi Tiến sĩ Edmund Fournier d’Albe phát minh ra máy thị âm để quét và chuyển hóa văn bản thành âm thanh cho người mù. Từ đó đến nay, OCR đã phát triển nhanh chóng trên thế giới trong mọi lĩnh vực liên quan đến xử lý hình ảnh. Việc ứng dụng của OCR rất đa dạng trong các ngành công nghiệp như xe tự lái (Self-driving Car), dịch máy (Image-based Machine Translation), hệ thống thu phí thông minh bằng hình ảnh (Electronic Toll Collection - ETC), tự động hóa quy trình bằng robot (Robotic Process Automation - RPA) hay lưu trữ sổ khám bệnh, đơn thuốc trong y tế mà chúng ta đã biết. Đối với lĩnh vực ngân hàng, từ phía người dùng, ứng dụng của OCR rõ hơn qua các tiện nghi mà các ứng dụng ngân hàng mang lại như làm thẻ online từ xa nhờ định danh khách hàng điện tử (electronic Know Your Customer - eKYC), rút tiền bằng chứng minh thư. Thời gian thực hiện giao dịch được giảm xuống nhờ việc kiểm tra thông tin có thể được thực hiện bằng máy móc mà không cần tới sự kiểm tra thủ công của con người.
Với sự gia tăng nhanh chóng về số lượng tài khoản ngân hàng và các giao dịch chi tiêu online, cũng như các ứng dụng đi động kết nối tới tài khoản ngân hàng, khối lượng dữ liệu đổ về ngân hàng với các giao dịch người dùng ngày một lớn hơn theo cấp số nhân. Ứng dụng OCR là điều kiện tiên quyết cho các ngân hàng đảm bảo đáp ứng được sự gia tăng dữ liệu này. Nếu mọi loại giấy tờ từ giấy vay, chứng minh thư, căn cước công dân, các loại hợp đồng, hóa đơn, ghi chú ngân hàng, giấy ủy quyền, báo cáo tài chính... đều được xử lý thủ công như truyền thống thì khó đáp ứng được yêu cầu về thời gian xử lý nhanh chóng như kỳ vọng. Sử dụng OCR, các ngân hàng có lợi thế hơn trong việc số hóa các tài liệu về một khối thống nhất, giúp ngân hàng chuẩn hóa được các dữ liệu, vận hành 24/7, đơn giản hóa quy trình, giảm các gánh nặng về hành chính, tối ưu hóa chí phí kinh doanh.
Trên thế giới, cụm từ AI từ năm 2019 đã trở thành một cụm từ phổ biến trong giới tài chính. Theo báo cáo toàn cầu của Phòng Thương mại quốc tế (ICC) năm 2020, 28% số lượng ngân hàng sử dụng OCR cho việc bóc tách dữ liệu và số hóa văn bản, bao gồm các ngân hàng lớn trong lĩnh vực tài chính như HSBC, Standard Chartered cùng với nhiều tổ chức tài chính khác. Nhiều ngân hàng khác ở Trung Quốc còn sử dụng OCR kết hợp với nhận diện khuôn mặt để cung cấp bảo mật 2 lớp ở cây ATM.
Tại Việt Nam, theo Chương trình Chuyển đổi số quốc gia đến năm 2025, định hướng đến năm 2030 của Chính phủ đã nêu rõ vai trò của các tổ chức tài chính ngân hàng trong công cuộc chuyển đổi số của đất nước. Bên cạnh đó, sự ảnh hưởng của đại dịch Covid-19 trên thế giới đã phần nào làm đẩy nhanh hơn quá trình số hóa toàn diện ngành Ngân hàng tại nước ta. Xu hướng này được áp dụng ở hầu hết các ngân hàng lớn như Ngân hàng TMCP Tiên Phong (TPBank) có hệ thống ATM tự động chạy 24/7 (LiveBank) hay Ngân hàng TMCP Bưu điện Liên Việt có LienViet24h... Đặc biệt là TPBank và Ngân hàng TMCP Quân đội (MB) đã ghi nhận hơn 80% giao dịch trên nền tảng số. Qua đó, thấy được một bức tranh toàn diện hơn về bối cảnh áp dụng số hóa ở Việt Nam hiện nay rất phù hợp cho ứng dụng OCR nói riêng và AI nói chung.
Ngày nay, OCR không chỉ phát triển mạnh với tiếng Latin mà còn có thể giải quyết các ngôn ngữ khác trên thế giới từ tiếng Ả Rập, Ấn Độ, Trung Quốc... kể cả các chữ tượng hình. Nó có thể xác định được cả văn bản scan và hình ảnh không phân biệt là chữ in hay chữ viết tay, hệ thống đều có thể xử lý được với độ chính xác cao. Với các quy định rất gắt gao về an toàn dữ liệu, bảo mật của ngành Tài chính, OCR có thể chạy trên cả các máy server của ngân hàng hay trên điện toán đám mây như là một dịch vụ thông qua các giao thức API.
Về phương pháp thực hiện, việc nhận diện chữ viết trong hình ảnh sẽ gồm 04 pha chính là tiền xử lý (Preprocessing); xác định vị trí chữ (Text Detection); nhận diện chữ (Text Recognition) và hậu xử lý (Postprocessing). Với pha 1 - tiền xử lý, ta sẽ loại bỏ các nhiễu trong hình ảnh, xoay ảnh về đúng chiều và chỉnh kích thước của ảnh. Pha 2 sẽ sử dụng hình ảnh sau khi đã được căn chỉnh sử dụng mô hình học sâu để nhận biết được đâu là các vùng có chữ viết trên hình ảnh. Sau đó sử dụng mô hình mạng thần kinh kết hợp với cơ chế chú ý (Attention Mechanism) để nhận diện các chữ viết tương ứng với các vùng chữ để cho ra được các chữ cái trong bảng chữ cái. Pha cuối cùng là bước hiệu chỉnh chữ thu được từ pha 3, giúp cải thiện kết quả thu được sao cho đúng chuẩn chữ tiếng Việt. Trên thế giới, cũng có rất nhiều cách thức và phương pháp khác nhau trong việc giải quyết bài toán OCR này cho tiếng Anh như: DB, CRAFT... Nghiên cứu này sử dụng hai trong số các mô hình đang đạt kết quả tốt nhất trên tiếng Anh hiện nay là CRAFT (để phát hiện chữ) và CLOVA_AI (để nhận diện chữ). Tuy nhiên, để đạt được kết quả tốt trên bộ dữ liệu của tiếng Việt thì nghiên cứu đã thực hiện một số thay đổi và cải tiến. Để minh chứng cho sự hiệu quả của giải pháp được đề xuất, các tác giả đã thực hiện kiểm thử với bộ dữ liệu SROIE 2019 tiếng Anh và VNOnDB gồm 1.146 đoạn văn tiếng Việt bao gồm 7.296 dòng với hơn 380.000 ký tự viết bởi 200 người khác nhau.
II. Tóm tắt cơ sở lý thuyết
1. Một số công nghệ chính được sử dụng trong giải pháp đề xuất
- Mạng thần kinh tích chập - CNN: Là một loại mạng thần kinh nhân tạo, nhận đầu vào thường là ảnh và sử dụng phép toán tích chập nhằm trích xuất thông tin của đối tượng.
- Mạng thần kinh hồi quy - RNN: Là mạng dùng để xử lý các bài toán dữ liệu dạng chuỗi với các đầu vào có kích thước khác nhau. Nó sử dụng thông tin đầu vào hiện tại và đầu vào trong quá khứ đã có để cho ra kết quả. Nói cách khác, theo trình tự thời gian, RNN kết nối các nút tạo thành một đồ thị dọc, cùng một đầu vào thì có thể tạo một đầu ra khác nhau dựa theo các đầu vào trước đó.
- Cơ chế chú ý (Attention Mechanism): Theo như nghiên cứu về nhận thức của con người, trong 3s đầu chúng ta cần xác định một vật thể là gì chỉ bằng một số đặc điểm nổi bật nhất của nó. Áp dụng tư tưởng đó, kỹ thuật Attention giúp mô hình tập trung vào những yếu tố nhất định, đặc trưng nhất trong dữ liệu. Trong lĩnh vực xử lý ảnh, Attention thường gồm 03 phần chính là bộ mã hóa (encoder), bộ giải mã (decoder), xen giữa nó là một vector biểu diễn ngữ cảnh (context vector). Encoder với đầu vào là ma trận các điểm ảnh, đầu ra cuối cùng là một context vector - nơi tóm gọn toàn bộ lượng thông tin của encoder. Từ đó, decoder dùng chính context vector, cùng trạng thái ẩn và đầu ra trước đó để dự đoán thông tin tiếp theo tại decoder qua từng bước thời gian (timestep).
- Mạng Resnet, mạng Unet, mạng VGG-16: Là các kiến trúc mạng CNN, được tạo thành từ một loạt các tầng CNN được thiết kế khác nhau.
- Batch normalization: Đây là một phương pháp chuẩn hóa dữ liệu, giúp việc huấn luyện một cách dễ dàng và nhanh chóng hơn bằng cách tối ưu hàm mục tiêu. Ngoài ra, nó còn giúp cho mô hình giảm được sự phụ thuộc vào các giá trị khởi tạo và tránh được phần nào sự quá khớp với bộ dữ liệu được huấn luyện.
- Skip connection: Cơ chế bỏ qua một số lớp trong mạng Neural và lấy đầu ra của một lớp làm đầu vào cho các lớp tiếp theo. Nó có vai trò nâng cao khả năng giữ những thông tin cần thiết, tránh mất mát thông tin khi ta tăng số lớp trong khi huấn luyện mạng học sâu.
2. Tổng quan giải pháp và quy trình đề xuất
Như đã đề cập, bài toán nhận dạng chữ viết trong hình ảnh có đầu vào là một ảnh và đầu ra là các từ tương ứng đúng với vị trí trên bức ảnh đó. Phương pháp được mô tả gồm 04 pha (Hình 1):
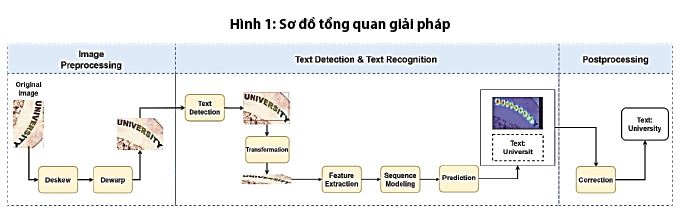
- Pha 1: Tiền xử lý, chuẩn hóa hình ảnh: chỉnh nhăn (dewarp), chỉnh lệch (deskew), chỉnh kích cỡ (resize).
- Pha 2: Sử dụng mô hình phát hiện ký tự văn bản (text detection) để tìm các vùng có chữ và xác định vị trí của nó trong bức ảnh.
- Pha 3: Nhận diện chữ trong các ảnh từ pha 2 bằng mô hình nhận diện ký tự văn bản (text recognition).
- Pha 4: Sửa lỗi văn bản đầu ra để gia tăng độ chính xác.
3. Mô tả chi tiết từng pha trong quy trình
Pha 1: Tiền xử lý
Ban đầu, hệ thống sẽ áp dụng các thuật toán liên quan đến xử lý ảnh để tăng chất lượng ảnh đầu vào. Lý do là bởi trong khi chúng ta scan tài liệu hay chụp ảnh tài liệu, bức ảnh thường bị nghiêng đi một góc tương đối so với chiều đúng của văn bản. Thêm vào đó, việc xử lý ảnh phóng to hay thu nhỏ sao cho tương thích với hệ thống không bị nghẽn khi ảnh quá lớn hay chất lượng tối thiểu khi ảnh quá nhỏ là điều cần thiết. Ngoài ra, với các văn bản giấy tờ trong ngân hàng hay các khối dịch vụ nói chung thường bao gồm rất nhiều dấu chấm nhỏ hay các nhiễu như hình ảnh chìm mà không cần thiết cho việc nhận diện chữ. Chúng ta sẽ loại bỏ các điểm ảnh này nhằm giảm bớt những vùng mà hệ thống cần dự đoán, giảm thiểu những lỗi có thể gặp phải.
Pha 2: Phát hiện vùng chứa chữ
Trong pha này, ta sẽ thực hiện việc phát hiện chữ viết trong ảnh. Như chúng ta đã biết, ảnh là một tập hợp bao gồm rất nhiều điểm ảnh, xác định bởi hai tọa độ theo chiều dọc và chiều ngang. Với các mạng thần kinh phát hiện chữ truyền thống chủ yếu là gộp các mạng CNN và RNN với nhau để trích chọn đặc trưng của chữ trong ảnh dựa trên từng điểm ảnh đó. Các đặc trưng ở đây được hiểu một cách đơn giản là các đặc điểm giúp ta nhận biết được đâu là chữ, đâu là ảnh nền, đâu là con dấu... dựa trên các đặc tính như đường nét, độ đậm nhạt, màu sắc, kích cỡ... của chữ. Những thông tin này trải qua việc huấn luyện các mạng thần kinh sẽ được học dần qua việc huấn luyện mô hình qua các bộ dữ liệu.
Đi sâu vào chi tiết mô hình phát hiện chữ nguyên bản mô hình CRAFT phát hiện chữ mà chúng tôi áp dụng, mạng gồm có cấu trúc cơ bản với khung là VGG-16 gồm 06 lớp CNN với batch normalization và các skip connection tương tự mạng U-net liên kết với các đặc trưng cấp thấp. Ta sẽ sử dụng mô hình mạng Neural để xác định vùng của các ký tự và vùng nối của các ký tự liền nhau làm đặc điểm chính để xác định phần nào của ảnh là ký tự chữ ở tầng cuối cùng của đầu ra. Thông thường việc đánh nhãn dữ liệu ở mức ký tự (đánh từng ký tự một của từ - character) là rất khó vì số lượng quá lớn với mỗi văn bản có chữ (thường sẽ được gán ở mức từ - word hoặc dòng - line). Do đó, để có thể được phát hiện ở mức ký tự trong phương pháp này, ta sẽ dùng dữ liệu từ 2 tập: Một là dữ liệu thực tế được gán nhãn ở mức từ và hai là dữ liệu không thực tế (ảnh được sinh ra hay tự tạo ra - Synthetic Image). Do tập dữ liệu thứ 2 là chúng ta tự tạo ra nên ta có thể kiểm soát được vị trí các ký tự trên bức ảnh một cách dễ dàng. Ta sẽ huấn luyện mô hình với bộ dữ liệu được tự gen trước để model học được các đặc trưng được model 1. Sau đó ta dùng model này để train với một phần ảnh thực tế được đánh nhãn ở mức từ tạo ra model 2. Ta sẽ tạo giả nhãn (pseudo ground truth) cho phần ảnh thực tế này bằng thuật toán watershed rồi điều chỉnh sao cho độ chính xác model 2 sẽ không thấp hơn độ chính xác của model 1. Kiểu huấn luyện với bộ data này được gọi là học có giám sát yếu (weakly supervised learning). Cuối cùng, ta sẽ dùng model này làm pretrain model (model đã được huấn luyện) để điều chỉnh tiếp với các data chưa được tạo nhãn giả dựa trên độ dài các từ (thông thường các nhãn của ảnh trên mức từ ta sẽ tính được độ dài ký tự trong đó). Nếu model 2 dự đoán ảnh từ tập này mà ngắn hơn so với nhãn của ảnh thì ta sẽ điều chỉnh lại. Cứ thế, ta sẽ điều chỉnh đến khi độ chính xác của mô hình đạt được kết quả cao. Đầu ra của pha này là các vùng chữ tương ứng với vị trí của nó (gồm 04 vị trí: Trái trên, phải trên, phải dưới, trái dưới tương ứng của khung chữ nhật).
Pha 3: Nhận diện các chữ
Pha này gồm 4 thành phần:
- Thành phần 1 (sự biến đổi): Chuẩn hóa và làm thẳng lại các chữ nghiêng, cong thành chữ nằm ngang bằng việc sử dụng mô hình STN.
- Thành phần 2 (trích chọn đặc trưng): Ta sử dụng cấu trúc Resnet làm cơ sở để trích xuất ra các thông tin. Đầu ra là một vector đặc trưng của ảnh.
- Thành phần 3 (mô hình hóa tuần tự): Ghi lại các thông tin trong một chuỗi tuần tự các ký tự để dự đoán chứ ta không dự đoán từng ký tự trong một từ.
- Thành phần 4 (dự đoán): Giải mã chuỗi đặc trưng dạng mã hóa ở phần 3 thành các ký tự chữ bằng việc sử dụng cơ chế Attention.
Về cơ bản, mô hình nhận diện sử dụng sức mạnh của sự kết hợp các mạng CNN và RNN rồi mở rộng với sự thêm mới thành phần chỉnh hình ảnh chữ trong không gian (thành phần biến đổi) và cải thiện quá trình dự đoán ở thành phần cuối bằng cơ chế Attention. Chúng tôi mở rộng so với mô hình ban đầu là tăng giới hạn của tham số độ dài tuần tự của trong một ảnh mà mô hình dự đoán và tăng số lượng trạng thái ẩn để thu giữ nhiều thông tin hơn. Việc điều chỉnh này tuy nhỏ nhưng có vai trò quan trọng trong việc dự đoán kết quả chính xác hơn. Ở đây, chúng tôi thay vì dự đoán từng từ tương ứng với mỗi vùng được xác định từ pha 3 thì có thể nhận diện được cả một cụm các từ trong ảnh (ảnh chỉ gồm 1 dòng các từ, theo chiều ngang). Do đó ta có thể nhận ra ngay, khi mà pha 3 xác định vùng không phải lúc nào cũng chỉ ra tương ứng mỗi ảnh là 1 từ thì ở đây với mỗi ảnh mà có 2 hay 3 từ thì việc dự đoán cũng có thể thực hiện được. Mặt khác, việc thay đổi này cũng giảm thời gian đánh nhãn của chúng ta, trở nên thuận tiện hơn bởi với mô hình gốc ta cần đánh nhãn mỗi ảnh (chỉ gồm 1 từ) với chữ của nó, khiến số lượng cần làm rất lớn. (Hình 2)

Pha 4: Sửa lỗi
Trong phần này, chúng ta sẽ sửa lỗi các từ có khả năng cao mắc lỗi từ kết quả pha 3. Chúng ta sử dụng 3 khả năng (dựa trên độ chính xác) từ phần nhận diện chữ kết hợp với một tập từ điển các từ thông dụng ở Việt Nam. Ngoài ra, nếu các từ được xác định trong ảnh thuộc về cùng một lĩnh vực hay ngành nghề thì ta có thể thu thập thêm các từ phổ biến của nó tạo thành một bộ các từ phổ biến trong lĩnh vực đó. Sau đó, ta gán trọng số theo thứ tự ưu tiên lần lượt cho: Kết quả từ pha 3, từ phổ biến trong từ điển gần giống nhất từ đó, từ phổ biến trong lĩnh vực gần giống từ đó. Chúng ta sẽ sắp xếp từ cao xuống thấp điểm của các từ ứng viên (candidate). Cơ chế này ta gọi là “scoring mechanism”. Cuối cùng, ta chọn từ ứng viên có điểm cao nhất làm kết quả cuối cùng của hệ thống.
III. Tính toán thử nghiệm
1. Mô tả dữ liệu
Chúng tôi sử dụng bộ dữ liệu Sroie 2019 cho mô hình phát hiện từ và bộ dữ liệu VNOnDB ở mức từ và câu để đánh giá kết quả của mô hình nhận diện.
- Sroie 2019: Bộ dữ liệu bao gồm các ảnh hóa đơn từ hơn 1.000 người nước ngoài. Chúng được chia làm 2 phần là tập huấn luyện/đánh giá gồm 600 ảnh và tập kiểm tra gồm 400 ảnh. Tương ứng với mỗi ảnh sẽ bao gồm các vùng chữ và nội dung của nó.
- VNOnDB: Bộ dữ liệu là các ảnh chữ viết tay của người Việt. Dữ liệu ban đầu là dạng ảnh tương ứng với các nét chữ online dạng xml, ta sẽ chuyển dữ liệu về dạng ảnh và chữ tương ứng trong ảnh đó. Ta chia bộ dữ liệu làm 3 phần: (Bảng 1, Hình 3)
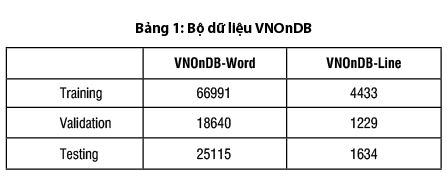

- Phần dữ liệu Training: Dùng để huấn luyện mô hình.
- Phần dữ liệu Validation: Dùng để đánh giá mô hình khi huấn luyện.
- Phần dữ liệu Testing: Dùng để kiểm tra kết quả của mô hình.
2. Tiêu chí đánh giá
Với module phát hiện chữ, ta sẽ đánh giá kết quả theo 3 tiêu chí gồm Precision, Recall, Hmean.
- Precision đo lường tỉ lệ dự đoán của mô hình là chính xác trong số các dự đoán.
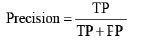
- Recall là tỉ lệ mô hình dự đoán đúng trên cả bộ dữ liệu được gán nhãn.
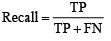
- Chỉ số Hmean là giá trị cân đối giữa Precision và Recall:
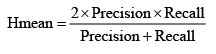
Trong đó:
- TP (True Positive): Là đối tượng được nhận dạng đúng với tỉ lệ IOU>0,5.
- FP (False Positive): Là đối tượng được nhận dạng đúng với tỉ lệ IOU<0,5.
- FN (False negative): Là đối tượng không được nhận dạng.
- IOU (Intersection over union): Là tỉ lệ giữa hai đường bao (thường là đường bao dự đoán - Predicted bounding box và đường bao thực - Ground truth bounding box) để xác định hai khung hình có bị đè chồng lên nhau không. Nó được tính bằng tỉ lệ diện tích giao nhau trên tổng hai diện tích. (Hình 4)

Tỉ lệ lỗi của các ký tự (Character error rate - CER) được sử dụng để đánh giá độ hiệu quả của mô hình nhận diện. Chỉ số CER được tính dựa trên độ đo khoảng cách (Edit distance). Giả sử hệ thống dự đoán ra là chuỗi A và nhãn thực tế của ảnh là B thì CER trên ảnh đó là:
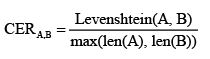
Trong đó: Levenshtein (A,B) là khoảng cách giữa chuỗi A và chuỗi B. Đó là số bước ít nhất để biến chuỗi A thành chuỗi B thông qua các phép biến đổi cơ bản; len(A), len(B) là độ dài của chuỗi A và độ dài của chuỗi B.
3. Kết quả thử nghiệm
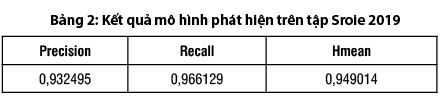
- Kết quả thử nghiệm của mô hình phát hiện trên tập Sroie 2019 (Bảng 2, Hình 5)

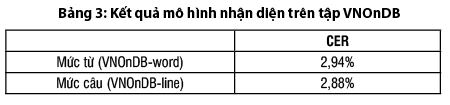
- Kết quả thử nghiệm của mô hình nhận diện trên tập VNOnDB (Bảng 3, Hình 6, Hình 7)


4. Đánh giá, nhận xét
Qua hai thử nghiệm về độ hiệu quả của mô hình ta thấy, hệ thống nhận dạng chữ viết có kết quả tốt trên cả bộ chữ in và chữ viết tay trong các điều kiện khác nhau. Từ đó ta có cái nhìn tổng thể hơn về các thuận lợi và khó khăn của việc áp dụng mô hình này vào các tổ chức tài chính, ngân hàng là:
Về thuận lợi:
- Dạng module dễ mở rộng.
- Có thể áp dụng với các kiểu chữ và ngôn ngữ khác nhau.
- Là cầu nối để chuyển đổi số, dễ dàng liên kết với các hệ thống trong ngân hàng như RPA, ERP.
Về khó khăn:
- Độ chính xác chỉ từ 90 - 99% => Cần người để sửa lỗi còn lại (BPO - Business process outsourcing).
- Cần xây dựng đội ngũ phát triển của các ngân hàng để hiểu nghiệp vụ và bóc tách các thông tin cần thiết sau OCR.
IV. Kết luận
Bài toán nhận diện chữ trong ảnh là một trong những bài toán kinh điển và quan trọng trong lĩnh vực ngân hàng nói riêng và các ngành công nghiệp ứng dụng khác nói chung. Các ngân hàng cần nhanh chóng đào tạo, bồi dưỡng, bổ sung cho cán bộ, nhân viên các kiến thức và hiểu biết nhất định về các công nghệ lõi để có thể triển khai một cách hiệu quả nhất bởi chuyển đổi số là xu thế tất yếu hiện nay. Khi mà dữ liệu ngày càng bùng nổ, ngân hàng nào có thể nắm bắt thì có thể phát triển rất nhanh chóng. OCR chính là cây cầu nối để thúc đẩy tiến trình đó. Bài viết đã mô tả chi tiết về một hệ thống nhận diện chữ viết bằng việc sử dụng các mô hình AI và học sâu để có thể nhận diện chữ tiếng Việt. Phương pháp áp dụng 04 thành phần cơ bản là tiền xử lý, phát hiện chữ, nhận diện chữ và hậu xử lý nhằm tìm ra các đặc trưng nhất để dự đoán các chữ trong ảnh. Với phương pháp này, các ngân hàng có thể tùy biến thêm, bớt các thành phần tùy theo từng điều kiện, trường hợp cụ thể một cách thích hợp nhất. Phương pháp hoạt động tương đối tốt với dữ liệu là các loại chữ Latin bao gồm có tiếng Việt. Bên cạnh đó, nó cũng có thể phát triển để có thể áp dụng cho nhiều loại ngôn ngữ khác.
Lời cảm ơn
Công trình nghiên cứu này được thực hiện bởi sự hỗ trợ của trường Đại học Bách khoa Hà Nội và Tập đoàn FPT.
Tài liệu tham khảo:
1. How does OCR reduce the risk of making a mistake? (finanteq.com).
2. Derek Rego, Amir Karimi, Sandra Peterson (2017), Machine Learning and Cognitive Computing: Enhancing Transaction Risk Management.
3. Y. LeCun, L. Bottou, Y. Bengio, P. Haffner. Gradient-based learning applied to document recognition. Proceedings of IEEE 86 (11) (1998) 2278 - 2324.
4. Alex Sherstinsky. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) Network. Physica D: Nonlinear Phenomena, Volume 404, 2020, 132306, ISSN 0167 - 2789.
5. I. Sutskever, O. Vinyals, and Q. V. Le. Sequence to sequence learning with neural networks. In Advances in neural information processing systems, pages 3104 -3112, 2014.
6. Youngmin Baek, Bado Lee, Dongyoon Han, Sangdoo Yun, and Hwalsuk Lee. Character region awareness for text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 9365 - 9374, 2019.
7. L. Vincent and P. Soille. Watersheds in digital spaces: an efficient algorithm based on immersion simulations. PAMI, (6): 583 - 598, 1991.
8. M. Jaderberg, K. Simonyan, A. Zisserman, et al. Spatial transformer networks. In Advances in neural information processing systems, pages 2017 - 2025, 2015.
KS. Vũ Minh Đức (Công ty FPT Software, Tập đoàn FPT)
ThS. Trần Thị Huế (Khoa Hệ thống thông tin Quản lý, Học viện Ngân hàng)
Tăng Thu Thảo, TS. Trần Ngọc Thăng (Viện Toán ứng dụng và Tin học, Đại học Bách khoa Hà Nội)
https://tapchinganhang.gov.vn























