Keywords: Earning management, machine learning.
1. Đặt vấn đề
Các công ty niêm yết trên sàn chứng khoán cố gắng thu hút vốn từ các nhà đầu tư và chủ nợ bằng cách thường xuyên công bố kết quả hoạt động tài chính thông qua báo cáo thu nhập và đáp ứng dự báo thu nhập của các nhà phân tích tài chính (Degeorge và cộng sự, 1999). Để đáp ứng mong đợi của các bên liên quan và không muốn bỏ lỡ những kì vọng này, quản lí một tổ chức có thể cố ý gây ảnh hưởng đến thu nhập được ghi nhận trong báo cáo tài chính (Rodriguez - Ariza và cộng sự, 2016). Hiện nay, bên cạnh các phương pháp truyền thống phổ biến được sử dụng trong việc phát hiện hành vi quản trị lợi nhuận như mô hình nghiên cứu của Jones (1991), Dechow và các cộng sự (mô hình Jones điều chỉnh, 1995); mô hình Kothari và cộng sự (2005), Raman và Shahrur (2008) còn có sự tích hợp các thuật toán học máy mang lại một giải pháp đầy hứa hẹn để nâng cao hiệu quả hoạt động kiểm toán, đặc biệt là trong việc phát hiện sự bất thường. Quản trị lợi nhuận được xác định qua các phương pháp này như thế nào và liệu phương pháp học máy có thực sự ưu việt hơn phương pháp đo lường truyền thống hay không? Đó cũng chính là mục đích hướng đến của bài nghiên cứu này.
2. Hành vi quản trị lợi nhuận
Thu nhập là yếu tố giải thích chính cho lợi nhuận và được các nhà phân tích, nhà đầu tư cũng như ban giám đốc coi là chỉ mục quan trọng cung cấp thông tin trong báo cáo tài chính (Bhojraj và cộng sự, 2009; Degeorge và cộng sự, 1999; Hazarika và cộng sự, 2012; Kothari và Sloan, 1992; Leuz và cộng sự, 2003). Các nhà điều hành, quản lí có thể cố ý gây ảnh hưởng đến thu nhập được ghi nhận trong báo cáo tài chính theo hướng hợp pháp hoặc bất hợp pháp (Rodriguez - Ariza và cộng sự, 2016) và hành động đó gọi là hành vi quản trị thu nhập hay quản trị lợi nhuận. Quản trị lợi nhuận có thể tác động hai mặt tới chất lượng báo cáo tài chính. Thứ nhất, quản trị lợi nhuận che giấu tình hình tài chính thực sự của doanh nghiệp và “che khuất” sự thật mà các bên liên quan có quyền được biết (Bajra và Cadez, 2018; Gunny, 2010; Lassoued và cộng sự, 2017). Quản trị lợi nhuận có thể dẫn đến mất danh tiếng (Rodriguez - Ariza và cộng sự, 2016) hoặc thậm chí là các vụ kiện pháp lí nếu có thể được coi là dấu hiệu của tham nhũng trong quản lí hoặc “nỗ lực” đánh lừa các nhà đầu tư (Gunny, 2010). Mặt khác, một số nhà nghiên cứu cũng đã chỉ ra những mặt tích cực của quản trị lợi nhuận (Bajra và Cadez, 2018; Jiraporn và cộng sự, 2008). Quản trị lợi nhuận được chia thành 2 loại: Quản trị lợi nhuận thực tế (Real Earnings Management - REM) và quản trị lợi nhuận dựa trên cơ sở dồn tích (Accruals Earnings Management - AEM). Cả hai hình thức đều làm tổn hại đến giá trị thông tin của báo cáo tài chính. Chính vì vậy, việc phát hiện hành vi quản trị lợi nhuận là một câu hỏi quan trọng trong nghiên cứu kế toán (Bhojraj và cộng sự, 2009; Dechow và Skinner, 2000; Efendi và cộng sự, 2007). Đa phần hoạt động quản trị lợi nhuận đều được thực hiện thông qua việc thao túng các khoản dồn tích vì các khoản dồn tích mang tính chủ quan do đó dễ dàng điều chỉnh. Nội dung bài viết chủ yếu tập trung vào các nghiên cứu xác định hành vi quản trị lợi nhuận thông qua các khoản dồn tích.
3. Yếu tố đo lường AEM
Kế toán dồn tích nhằm mục đích ghi lại các tác động kinh tế đối với một công ty có liên quan đến tiền mặt diễn ra trong các giai đoạn thay vì chỉ đơn thuần là thu, chi (Dechow và Skinner, 2000). Hệ thống kế toán này cung cấp quyền kiểm soát quản lí đối với việc lựa chọn và cho phép ban quản lí sử dụng quyền quyết định vốn có trong hệ thống để xác định thu nhập được báo cáo nhằm đạt được mục đích. Nghĩa là, các nhà quản lí sử dụng phán đoán của mình dựa trên thông tin có sẵn để ước tính các khoản mục khác nhau được công bố trong báo cáo tài chính (Al - Sraheen, 2019; Fang và cộng sự, 2016).
Việc đánh giá quyền quyết định của nhà quản lí đối với thu nhập là rất quan trọng để khám phá quản trị lợi nhuận. Các khoản dồn tích thay đổi thời điểm báo cáo thu nhập và cho phép ban quản lí chuyển thu nhập giữa các kì báo cáo. Trong đó, các khoản dồn tích không tùy ý nằm ngoài tầm kiểm soát của nhà quản lí vì đây là kết quả của các hoạt động thường ngày của công ty, trong khi các khoản dồn tích tùy ý phát sinh từ các lựa chọn của ban quản lí (Dechow và cộng sự, 1995). Theo các nghiên cứu, một lượng lớn các khoản dồn tích tùy ý cho thấy một công ty đang tham gia vào AEM. Do đó, các khoản dồn tích tùy ý được xem là yếu tố để nắm bắt phạm vi của AEM.
4. Phương pháp nghiên cứu
4.1. Tiếp cận theo hướng truyền thống - Mô hình Jones điều chỉnh
Các nghiên cứu trước đây cho thấy, phương pháp AEM không ảnh hưởng đến hoạt động hiệu quả tài chính dài hạn của công ty (Cohen và Zarowin, 2010; Dechow và cộng sự, 2012). Dechow và cộng sự (1995) đã đánh giá hiệu quả hoạt động (dựa trên sức mạnh của các mô hình) của 5 kĩ thuật đo AEM: Mô hình Jones (Jones, 1991), mô hình Jones điều chỉnh (Dechow và cộng sự, 1995), mô hình DeAngelo (DeAngelo, 1986), mô hình Dechow và Sloan (Dechow và Sloan, 1991) và mô hình Healy (Healy, 1985). Những phát hiện chứng minh rằng, mô hình Jones điều chỉnh xác định được mức độ của AEM hiệu quả nhất. Dechow và cộng sự cho rằng, thông số kĩ thuật tiêu chuẩn của Jones không nắm bắt được hết tác động của việc thao túng dựa trên doanh số bán hàng, do thực tế cho thấy, những thay đổi về doanh số bán hàng được coi là mang lại lợi ích, tăng lên các khoản dồn tích không tùy ý. Trong phiên bản mới hơn này, mô hình bổ sung thêm biến nợ phải thu vào mô hình gốc. Thay đổi duy nhất so với mô hình đầu tiên của Jones là những thay đổi về doanh thu được điều chỉnh phù hợp với sự thay đổi của các khoản phải thu trong thời gian diễn ra sự kiện. Phiên bản sửa đổi đưa ra giả định rằng, tất cả các thay đổi về doanh thu trả chậm trong thời gian diễn ra sự kiện là kết quả của việc quản lí thu nhập do thực tế là thu nhập được quản lí dễ dàng hơn thông qua việc thực hiện quyền quyết định đối với việc xác nhận doanh thu bán hàng trả chậm hơn là thông qua việc thực hiện quyền quyết định đối với việc bán hàng bằng tiền mặt.
Trong mô hình Jones điều chỉnh, các khoản phải thu được tính vào doanh thu vì chúng có thể liên quan đến việc điều chỉnh quản trị lợi nhuận, sử dụng biến (∆REVit - ∆RECit) thay cho biến ∆REVit, ngầm giả định rằng tất cả những thay đổi về doanh thu từ các khoản phải thu là do quản trị lợi nhuận.
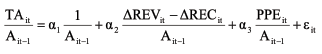
Tổng các khoản dồn tích = Các khoản dồn tích không tùy ý + Các khoản dồn tích tùy ý.
Trong đó:
∆REVit : Chênh lệch doanh thu của công ty i trong năm t và t-1.
∆RECit: Chênh lệch các khoản phải thu thuần của công ty i trong năm t và t-1.
PPEit : Tổng tài sản, nhà xưởng và thiết bị của công ty i năm t.
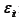 : Sai số trong năm t đối với công ty i.
: Sai số trong năm t đối với công ty i.
4.2. Tiếp cận theo hướng hiện đại - Mô hình cây quyết định
Nhóm mô hình học máy cây quyết định bao gồm các thuật toán dựa trên cấu trúc cây để thực hiện các nhiệm vụ học có giám sát như phân loại và hồi quy. Các thuật toán học máy có giám sát được sử dụng phổ biến nhất trong việc phát hiện hành vi thao túng quản lí thu nhập và phát hiện gian lận tài chính như phương pháp rừng ngẫu nhiên (Random forest - RF), phương pháp cây quyết định (Decision tree), đây cũng chính là những mô hình nổi bật của hướng nghiên cứu này. Mô hình này dựa trên việc chia tập dữ liệu thành các nhóm nhỏ hơn bằng cách sử dụng quyết định dựa trên giá trị của các thuộc tính. Các thuật toán này có ưu điểm là dễ hiểu, dễ giải thích và hiệu quả trong việc xử lí các loại dữ liệu khác nhau.
Việc xây dựng mô hình học máy để phát hiện hành vi thao túng quản lí thu nhập, phát hiện gian lận tài chính thường trải qua các bước sau:
Bước 1: Thu thập dữ liệu
Đây là bước đầu tiên trong tất cả các nhiệm vụ học máy, nhằm lấy dữ liệu, cả về số lượng lẫn chất lượng. Dữ liệu này có thể là báo cáo tình hình tài chính của công ty có sẵn trên website chính thức của công ty hoặc hệ thống dữ liệu Fiinpro. Dữ liệu này được sử dụng để đào tạo và thử nghiệm thuật toán học máy.
Bước 2: Chuẩn bị dữ liệu
Bước này nhằm xử lí các giá trị bị thiếu, loại bỏ các phần tử nhiễu, thống nhất thang đo số trong dữ liệu. Đây được coi là một bước rất quan trọng trong việc chuẩn bị sẵn sàng dữ liệu để xây dựng mô hình học máy thành công và tăng cường độ chính xác của mô hình. Sau đó, chia dữ liệu thành hai phần, tức là đào tạo và kiểm tra.
Phần đào tạo sẽ được sử dụng để dạy thuật toán học máy, trong khi phần kiểm tra sẽ được sử dụng để đánh giá hiệu suất của mô hình đã tạo.
Các phương pháp nghiên cứu sử dụng trong nghiên cứu như:
- Mô hình RF: Bản chất của thuật toán RF là không hoàn toàn dựa trên quyết định của một cây để ra quyết định mà có thể kết hợp được nhiều cây để có kết quả phân loại rõ ràng hơn. Do đó, RF có thể khắc phục nhược điểm là giảm lỗi sai sót trong dự đoán và đem đến hiệu suất dự đoán cao hơn. Các mô hình RF phổ biến do độ chính xác cao và chi phí tính toán tương đối thấp (T.Le và cộng sự, 2023).
- Phương pháp cây quyết định: Cây quyết định là một công cụ phân loại trong học máy, nơi các quyết định được thực hiện dựa trên thuộc tính của dữ liệu. Trong bối cảnh phát hiện hành vi gian lận, cây quyết định thường sử dụng Entropy hoặc chỉ số Gini để tối ưu hóa quá trình phân loại, nhằm phân biệt giao dịch gian lận với giao dịch hợp pháp. Cây quyết định có thể được sử dụng cho cả vấn đề phân loại và hồi quy. Thuật toán này được sử dụng để phân tích các tập dữ liệu lớn dựa trên quy tắc chia, mang lại dự đoán tốt nhất. Ngoài việc không bị ảnh hưởng bởi bất kì giả thuyết thống kê nào về dữ liệu mẫu, đặc điểm chính của cây quyết định là khả năng xử lí một phần dữ liệu và kiểm tra mối quan hệ tiềm năng giữa các biến đầu vào và đầu ra lớn, phức tạp.
Bước 3: Xây dựng mô hình
Bước này là nơi phần đào tạo dữ liệu kết nối với thuật toán học máy. Thuật toán này tận dụng mô hình toán học phức tạp để tìm hiểu dữ liệu và đưa ra dự đoán.
Bước 4: Thử nghiệm mô hình
Bước này được sử dụng để xác thực mô hình đã xây dựng từ bước trước đó trong phần kiểm tra tập dữ liệu và kiểm tra hiệu suất theo bất kì số liệu đo lường nào thông qua ma trận nhầm lẫn (Confusion matrix), các chỉ số đánh giá từ ma trận như độ chính xác (Accuracy), độ nhạy (Recall), Precision và điểm F1 (F1 Score) là các thước đo toán học rộng rãi nhất được sử dụng để đánh giá hiệu suất của các phương pháp học máy… Nếu kết quả thu được không đạt yêu cầu, quy trình nên quay lại quá trình đào tạo hoặc thậm chí quay lại bước chuẩn bị dữ liệu.
Bước 5: Hiển thị kết quả
Đây là bước cuối cùng nhằm hiển thị kết quả thu được từ các bước trước đó (bước huấn luyện và kiểm tra) trong dạng bảng hoặc biểu đồ như đường, thanh, hình tròn... bằng cách sử dụng một trong các công cụ trực quan hóa phân tích như Excel.
Về biến nghiên cứu, các mô hình học máy cũng sử dụng bộ dữ liệu của phương pháp truyền thống. Những khoản dồn tích tùy ý được sử dụng làm biến đại diện cho quản trị lợi nhuận trong các nghiên cứu học máy này. Khoản dồn tích không tùy ý được trừ khỏi tổng số dồn tích để đạt được số dồn tích tùy ý. Bảng cân đối kế toán và báo cáo lưu chuyển tiền tệ là hai báo cáo cơ bản để tính tổng các khoản dồn tích. Vì dùng chung một bộ số liệu nên đây là căn cứ quan trọng để chúng ta xem xét đến tính hiệu quả của các mô hình với nhau. Liệu rằng mô hình học máy có hiệu quả hơn phương pháp truyền thống hay không, có nâng cao khả năng nhận biết kịp thời hoặc đánh giá được rủi ro phù hợp không?
5. So sánh tính hiệu quả
Học máy hiện tại đang được sử dụng trong ngân hàng để phát hiện gian lận, chẳng hạn như chuẩn đoán khủng hoảng tài chính và hiệu quả hoạt động của ngân hàng. Khả năng của máy tính làm cho các kĩ thuật học máy hiệu quả hơn trong việc xử lí các vấn đề tài chính lớn. Các nghiên cứu trên cho thấy, khoa học dữ liệu có khả năng dự đoán tốt hơn so với phương pháp thống kê thông thường. Các phương pháp kiểm toán truyền thống, kiểm định mô hình truyền thống có thể không còn phù hợp trong bối cảnh tích hợp liên tục giữa tiến bộ công nghệ và doanh nghiệp hiện nay.
Nghiên cứu của B. Dbouk và I. Zaarour (2017) cho thấy, các mô hình toán học hoạt động tốt hơn các kiểm toán viên. Nghiên cứu chỉ ra rằng, các phương pháp của kiểm toán viên thủ công rất khó phát hiện quản trị lợi nhuận trên báo cáo tài chính, cụ thể, tỉ lệ phân loại là 86,84% khi sử dụng mô hình Beneish, là 60,53% khi áp dụng phương pháp của kiểm toán viên thủ công.
Nghiên cứu của Fu-Hsiang Chen và Hu Howard (2015) sử dụng phương pháp lai được đề xuất để sàng lọc các biến ngay từ đầu, sau đó áp dụng ba loại cây quyết định bao gồm bộ phát hiện tương tác tự động Chi bình phương, cây phân loại và hồi quy, sử dụng phương pháp lai để thiết lập một mô hình và tìm hiểu xem doanh nghiệp được thử nghiệm có bị thao túng thu nhập quá mức hay không. Kết quả cho thấy, phương pháp lai được đề xuất có tỉ lệ phân loại tối ưu (tỉ lệ chính xác là 91,24%) và tỉ lệ xảy ra lỗi thấp nhất.
Theo Faozi A. Almaqtari và cộng sự (2021), các nghiên cứu trước đây về tối ưu hóa quản lí thu nhập không mang lại sự tối ưu hóa lí tưởng cho việc quản lí thu nhập. Nghiên cứu hiện tại thông qua học máy mang lại những kiến thức hữu ích để dự đoán và tối ưu hóa việc quản lí thu nhập và gian lận tài chính, có ý nghĩa quan trọng đối với các nhà hoạch định chính sách, thị trường chứng khoán, kiểm toán viên, nhà đầu tư, nhà phân tích và chuyên gia.
6. Kết luận
Các hệ thống kiểm toán truyền thống với hạn chế về thời gian, nguồn nhân lực, chi phí có thể gặp khó khăn trong việc phát hiện các hoạt động bất thường trong dữ liệu tài chính rộng lớn và phức tạp. Do đó, việc phát triển mô hình dự đoán quản trị lợi nhuận khá hữu ích cho kiểm toán viên, nhà đầu tư trong việc xác định mức độ thao túng báo cáo tài chính. Hiện tại, ở Việt Nam, nghiên cứu áp dụng mô hình học máy để dự đoán hành vi quản trị lợi nhuận trong kế toán còn hạn chế. Đối với kiểm toán viên, mô hình này sẽ có chi phí thấp hơn so với các phương pháp truyền thống, vì việc khai thác dữ liệu diễn ra nhanh hơn, do đó tiết kiệm thời gian, đồng thời cung cấp thông tin bổ sung có thể giúp kiểm toán viên thực hiện phân tích, xác định rủi ro kiểm toán (tác động đến việc thiết kế kế hoạch kiểm toán) và thủ tục kiểm tra. Đối với các nhà đầu tư, việc xác định quản trị lợi nhuận tiềm năng có thể giúp gây áp lực lên ban giám đốc để giám sát chặt chẽ hơn trong trình bày thông tin trên báo cáo tài chính. Các ngân hàng có thể sử dụng mô hình phân tích này để hỗ trợ trong quá trình đánh giá hồ sơ tín dụng của người đi vay.
TÀI LIỆU THAM KHẢO:
1. B. Dbouk and I. Zaarour, (2017), “Financial Statements Earnings Manipulation Detection Using a Layer of Machine Learnin”, International Journal of Innovation, Management and Technology, Vol. 8, No. 3, June 2017.
2. Bernardo D, Hagras H, Tsang E (2013), “A genetic type-2 fuzzy logic based system for the generation of summarised linguistic predictive models for financial applications” Soft Comput 17(12): pages 2185- 2201.
3. Bhojraj, S., Hribar, P., Picconi, M., and McInnis, J, (2009). “Making sense of cents: An examination of firms that marginally miss or beat analyst forecasts”, Journal of Finance, 64(5): pages 2361- 2388.
4. Dechow, P. M., & Dichev, I. D, (2002), “The quality of accruals and earnings: The role of accrual estimation errors”, The accounting review, 77(s-1), pages 35-59.
5. Dechow, P. M., Sloan, R. G., & Sweeney, A. P, (1995), “Detecting earnings Management”, Accounting review, pages 193-225
Degeorge, F., Patel, J., and Zeckhauser, R, (1999), “Earnings management to exceed thresholds” Journal of Business, 72(1): pages 1-33.
6. Efendi, J., Srivastava, A. & Swanson, E.P. (2007), ‘Why do corporate managers misstate financial statements? The role of option compensation and other factors”, Journal of Financial Economics, 85(3), pages 667-708.
7. F.-H. Chen, H. Howard, (2016), “An alternative model for the analysis of detecting electronic industries earnings management using stepwise regression, random forest, and decision tree”, Soft Computer (2016) 20:1 pages 945-1960, DOI 10.1007/s00500-015-1616-6.
8. Faozi A. Almaqtari et al. (2021), “Earning management estimation and prediction using machine learning: A systematic review of processing methods and synthesis for future Research”, 2021 International Conference on Technological Advancements and Innovations (ICTAI).
9. Fethi MD, Pasiouras F (2010), “Assessing bank efficiency and performance with operational research and artificial intelligence techniques: a survey”, The European Journal of Operational Research, 204(2), pages 189-198.
10. Hsu MF, Pai PF (2013), “Incorporating support vector machines with multiple criteria decision making for financial crisis analysis”, Quality Quantity 47(7), pages 3481-3492.
11. Kothari, S. P., Leone, A. J., & Wasley, C. E. (2005), “Performance matched discretionary accrual measures”, Journal of accounting and economics, pages 163-197.
12. Lassoued, N„ Sassi, H. & Attia, M.B.R. (2016), “The impact ofstate and foreign ownership on banking risk: Evidence from the MENA countries”, Research in International Business and Finance, pages 167-178.
13. Levitt Jr, A. (1998). The numbers game. The CPA Journal, 68(12).
14. Raman, K., & Shahrur, H, (2008), “Relationship-specific investments and earnings management: Evidence on corporate suppliers and customers”, The accounting review, pages 1041-1081.
15. Rodriguez-Ariza, L., Martínez-Ferrero, J., & Bermejo-Sanchez, M, (2016), “Consequences of earnings management for corporate reputation: Evidence from family firms” Accounting Research Journal, 29(4), pages 457-474. https://doi.org/10.1108/ARJ-02-2015- 0017
16. Shen KY, Tzeng GH (2014), “A decision rule-based soft computing model for supporting financial performance-improvement of the banking Industry”, Soft Comput. in Press. doi:10.1007/s00500-014-1413-7.
17. T. Le et al, (2021), “Using Machine Learning to Predict the Defaults of Credit Card Clients. Fintech with Artificial Intelligence, Big Data, and Blockchain, Blockchain Technologie”s, https://doi.org/10.1007/978-981-33-6137-9_4
18. Tran Kim Long et al (2022), “Explainable Machine Learning for Financial Distress Prediction: Evidence from Vietnam”. Data 2022, 7, 160. s Note: MDPI stays neutral with regard to jurisdictional claims in published, https://doi.org/10.3390/data7110160.
19. Tran Kim Long et al, (2023). Machine Learning to Forecast Financial Bubbles in Stock Markets: Evidence from Vietnam. International Journal of Financial Studies 11: 133. https:// doi.org/10.3390/ijfs11040133
20. Verikas A, Kalsyte Z, Bacauskiene M, Gelzinis A (2010), “Hybrid and ensemble-based soft computing techniques in bankruptcy prediction: a survey”, Soft Computer 14(9), pages 995-1010.
ThS. Trần Thị Tuyết Vân
Trường Đại học Ngân hàng Thành phố Hồ Chí Minh