1. Giới thiệu
Do không đủ lịch sử tín dụng, nhiều người gặp khó khăn trong việc vay vốn từ các nguồn đáng tin cậy chẳng hạn như ngân hàng. Những đối tượng này thường là sinh viên hoặc người thất nghiệp, những người không có cơ sở để chứng minh độ tin cậy đối với bên cho vay. Những tổ chức cho vay không chính thống có thể lợi dụng các đối tượng này bằng cách lấy lãi suất cao hoặc đưa ra các điều khoản ẩn trong hợp đồng. Thay vì đánh giá khách vay dựa trên điểm tín dụng, có nhiều cách thay thế khác để dự đoán khả năng trả nợ của họ. Ví dụ, việc làm có thể là một yếu tố ảnh hưởng lớn đến khả năng trả nợ của một người vì việc làm giúp con người có thu nhập và dòng tiền ổn định hơn. Bên cạnh đó, một số yếu tố khác như bất động sản, tình trạng hôn nhân và nơi cư trú cũng có thể hữu ích trong việc đánh giá khả năng trả nợ.
Những năm gần đây, sự phát triển mạnh mẽ của học sâu (Deep Learning) đã mang lại nhiều đóng góp to lớn trong việc xây dựng các mô hình dự đoán. Do đó, trong bài viết này, tác giả dự định sử dụng thuật toán học sâu để nghiên cứu mối tương quan giữa tình trạng của khách vay và khả năng trả nợ của họ. Trong mô hình, tác giả sử dụng bộ dữ liệu Home Credit Default Risk, gồm dữ liệu của 308.000 khách hàng ẩn danh với 122 đặc trưng. Bằng cách nghiên cứu mối tương quan giữa các đặc trưng này và khả năng trả nợ của khách hàng, mô hình trong bài viết có thể giúp các TCTD đánh giá khách vay từ nhiều khía cạnh hơn từ đó dự đoán được rủi ro tín dụng.
2. Cơ sở lí thuyết
2.1. Hoạt động cho vay
Cho vay là một hình thức cấp tín dụng, theo đó TCTD giao cho khách hàng một khoản tiền để sử dụng vào mục đích và thời hạn nhất định theo thỏa thuận với nguyên tắc hoàn trả cả gốc và lãi. Cho vay là hoạt động sinh lời lớn nhất song cũng có rủi ro cao nhất của các TCTD, chính vì vậy để TCTD có thể tồn tại và phát triển vững chắc thì hoạt động cho vay cần phải an toàn và hiệu quả.
Khả năng trả nợ của khách hàng là việc khách hàng có khả năng trả nợ đầy đủ và đúng hạn với bên cho vay hay không. Hiện tại vẫn chưa có định nghĩa thống nhất về khái niệm “khả năng trả nợ” mà chỉ có những dấu hiệu về việc khách hàng “không có khả năng trả nợ”, thông qua phương pháp loại trừ, có thể hiểu ngoài những khách hàng “không có khả năng trả nợ” là những khách hàng “có khả năng trả nợ”.
Theo Hiệp ước Basel II, hai tình trạng sau có thể dùng làm căn cứ để đánh giá khả năng không trả được nợ của khách hàng:
- Khách hàng không có khả năng thực hiện nghĩa vụ thanh toán đầy đủ khi đến hạn mà chưa tính đến việc ngân hàng bán tài sản (nếu có) để hoàn trả.
- Khách hàng có các khoản nợ xấu thời gian quá hạn trên 90 ngày. Trong đó, những khoản thấu chi được xem là quá hạn khi khách hàng vượt hạn mức hoặc được thông báo một hạn mức nhỏ hơn dư nợ hiện tại.
Thông qua định nghĩa của IMF và các dấu hiệu mà Hiệp ước Basel II mô tả có thể thấy, thông thường việc khách hàng phát sinh nợ xấu đồng nghĩa với việc khách hàng không có khả năng trả nợ.
2.2. Dự đoán rủi ro tín dụng
Các TCTD thường đánh giá khả năng trả nợ của khách hàng và rủi ro khi cho họ vay tiền. Căn cứ vào khả năng trả nợ và rủi ro, TCTD đặc biệt là ngân hàng có thể điều chỉnh lãi suất của các khoản vay cho khách hàng.
Việc nghiên cứu đánh giá khả năng trả nợ của khách hàng đã được các TCTD, nhà nghiên cứu thực hiện trong nhiều thập kỉ. Một số nghiên cứu tập trung vào việc tìm kiếm các thang đo hữu ích để đánh giá định lượng khả năng trả nợ của khách hàng, chẳng hạn như tỉ lệ chênh lệch thu nhập với chi tiêu hằng tháng và điểm tín dụng.
Bên cạnh đó, để ngăn chặn và giảm tỉ lệ rủi ro khi thanh toán khoản vay, Cục Bảo vệ tài chính người tiêu dùng (CFPB) đã đưa ra một bộ quy tắc và quy định mới để đánh giá khả năng trả nợ của người cho vay. Các quy tắc và quy định là các thông tin của khách vay bao gồm: Thu nhập hoặc tài sản đảm bảo; tình trạng việc làm; khoản thanh toán dự kiến hằng tháng; thanh toán hằng tháng cho các khoản vay, thanh toán thế chấp hằng tháng; tình trạng nợ hiện tại; thu nhập thặng dư; lịch sử tín dụng.
Những yếu tố này trở thành quy tắc chung để đánh giá khả năng trả nợ của khách hàng cũng chính là rủi ro tín dụng. Tuy nhiên, các quy tắc về khả năng trả nợ này có thể không phù hợp để đánh giá một số nhóm người cho vay. Ví dụ, sinh viên đại học có thể không đáp ứng các điều kiện để vay tiền từ các nguồn đáng tin cậy, chẳng hạn như ngân hàng, vì họ không có việc làm và lịch sử tín dụng rất hạn chế. Do đó, những người cho vay không đáng tin cậy có thể lợi dụng họ. Để ngăn chặn điều này xảy ra, mục tiêu của bài viết này là khám phá các đặc trưng hữu ích và dễ nhận biết hơn để đánh giá độ tin cậy và khả năng trả nợ của khách hàng. Ngoài ra, đóng góp của bài viết đó là tiến hành huấn luyện và thử nghiệm các mô hình học máy dựa trên các đặc trưng và tìm ra mô hình tốt nhất để dự đoán khả năng trả nợ của khách hàng.
3. Phương pháp
Mục tiêu của bài viết là dự đoán rủi ro tín dụng, cụ thể là dự đoán khả năng trả nợ của khách hàng dựa trên các yếu tố khác ngoài lịch sử tín dụng. Nó có thể được đưa về bài toán phân loại nhị phân. Phần tiếp theo sẽ giới thiệu các phương pháp tác giả đã sử dụng để tiền xử lí dữ liệu và các thuật toán học sâu được sử dụng để giải quyết vấn đề.
3.1. Tiền xử lí dữ liệu
Bộ dữ liệu được sử dụng để huấn luyện và thử nghiệm là bộ dữ liệu mẫu Kaggle, Home Credit Default Risk. Do tính phức tạp của dữ liệu thô, tác giả sẽ giới thiệu một số kĩ thuật tiền xử lí dữ liệu cho tập dữ liệu của mình trước khi sử dụng để huấn luyện và thử nghiệm.
Chọn thuộc tính
Dữ liệu gồm nhiều biến hay thuộc tính, tuy nhiên, không phải tất cả các thuộc tính đó đều ảnh hưởng đến biến mục tiêu. Những biến như vậy sẽ gây ra nhiễu cho mô hình. Mặc dù mô hình sẽ tự chọn ra các đặc trưng tốt nhất thông qua quá trình học. Tuy nhiên, đôi khi cũng xảy ra trường hợp mô hình cho rằng các thuộc tính đó quan trọng, làm giảm đi hiệu quả của mô hình.
Bên cạnh đó, do giới hạn phần cứng của nền tảng Google Colab nên tác giả quyết định giảm tải bớt một số thuộc tính không quan trọng hoặc ít quan trọng, ví dụ như thuộc tính Organizatio-type hay loại hình công việc của khách hàng, vì suy cho cùng việc trả nợ sẽ tập trung vào thu nhập bao nhiêu hơn là làm ngành gì. Tương tự có thể kể đến các thuộc tính như Name-type-suite để đánh dấu ai đi cùng khách hàng đến vay, thuộc tính Weekday-appr-process-start cho biết khách hàng đến vay vào ngày nào...
Biến đổi các dữ liệu không phải số
Thư viện Keras mà tác giả sử dụng để tạo mô hình không thể xử lí các dữ liệu dạng chữ, nên cần phải chuyển đổi nó thành các dạng dữ liệu khác để có thể huấn luyện mạng nơ-ron.
One-Hot Encoding là một cách biến đổi thích hợp cho các dữ liệu dạng chữ. Từ thuộc tính ban đầu sẽ tách thành số thuộc tính tương đương với số giá trị nó có, sau đó sẽ đánh giá trị nhị phân với các thuộc tính mới, giá trị là 1 nếu thuộc tính mới chính là giá trị của bản ghi ban đầu. Với thuộc tính Contract-type có hai giá trị là Cash loans và Revolving loans sẽ được tách thành hai thuộc tính mới là Contract-type-cashloans và Contract-type-revolvingloans.
Tích hợp dữ liệu
Sau khi đã biến đổi dữ liệu để phù hợp cho thuật toán, cần gộp chung dữ liệu các bảng tạo thành một bảng lớn duy nhất để huấn luyện mô hình.
Làm sạch dữ liệu
Là quá trình xử lí và loại bỏ các lỗi, thiếu sót, hoặc thông tin không chính xác khỏi tập dữ liệu. Mục tiêu của việc làm sạch dữ liệu là đảm bảo rằng dữ liệu được sử dụng trong quá trình phân tích hoặc huấn luyện mô hình là chính xác, đầy đủ và đáng tin cậy. Các công việc thường thấy trong làm sạch dữ liệu:
- Giá trị ngoại vi (outlier): Các giá trị cao hoặc thấp một cách bất thường, đôi khi có thể là giá trị vô hạn. Các giá trị này khiến cho mô hình học từ những trường hợp rất ít khi xảy ra và ảnh hưởng tới dự đoán của nó cho các trường hợp bình thường. Để tiện xử lí, mô hình sẽ đưa nó về giá trị null (không có giá trị) và xử lí cùng với nhóm sau.
- Giá trị bị thiếu: Đối với các giá trị null hay NaNs (không được xác định), có nhiều cách để xử lí. Nếu phần null quá lớn ta sẽ buộc phải bỏ cả cột kết quả đó đi vì giá trị null quá lớn không có tác dụng cho mô hình. Nếu tỉ lệ null nhỏ hơn, ta có thể cân nhắc cho chúng thành 0, thành giá trị trung bình của tập dữ liệu hoặc đôi khi là giá trị xuất hiện nhiều nhất trong thuộc tính đó.
Chia tập dữ liệu
Chia tập dữ liệu (Data Splitting) là việc chia dữ liệu thành hai (đôi khi là ba) tập dữ liệu con với mục đích để huấn luyện và kiểm thử mô hình. Tập dữ liệu đầu tiên để huấn luyện, sẽ giúp mô hình học từ các dữ liệu trong nó và điều chỉnh để dự đoán nó đúng hơn. Tập thẩm định dùng để đánh giá mô hình trong quá trình huấn luyện. Sau đó sẽ dùng mô hình dự đoán các giá trị trong tập kiểm thử.
3.2. Mô hình mạng nơ-ron sâu (Deep Neural Network - DNN)
DNN là một tiến bộ tương đối mới trong lĩnh vực lập trình mạng nơ-ron. Về bản chất, bất kì mạng nơ-ron nào có nhiều hơn hai lớp được coi là sâu. Khả năng tạo ra DNN đã tồn tại kể từ khi Pitts (1943) giới thiệu Perceptron đa lớp (mô hình mạng nơ-ron mạnh mẽ cho phép học các hàm phi tuyến tính đối với dữ liệu phức tạp). Tuy nhiên, việc huấn luyện mạng nơ-ron trở nên thực sự hiệu quả khi Hinton (1984) trở thành nhà nghiên cứu đầu tiên thành công trong việc huấn luyện những mạng nơ-ron phức tạp này.
Cấu trúc mạng nơ-ron sâu khá tương đồng với cấu trúc của mạng nơ-ron nông (Shallow neural network). Sự khác biệt chủ yếu nằm ở số lớp ẩn. Số lớp ẩn nhiều hơn so với 1, mạng nơ-ron được coi là sâu. (Hình 1)
Hình 1: Cấu trúc mạng nơ-ron sâu
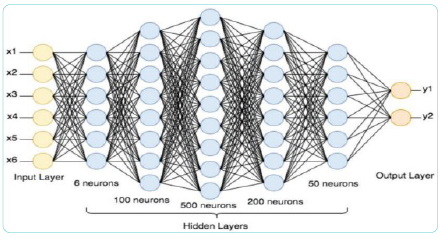
Nguồn: Tác giả phân tích
Để tạo DNN cần phải thông qua ba bước chính:
- Định nghĩa kiến trúc của mạng và đầu vào, đầu ra.
- Huấn luyện mạng sử dụng dữ liệu huấn luyện với biến mục tiêu rõ ràng.
- Kiểm thử hiệu suất của mạng.
Tạo mạng nơ-ron
Sau khi chuẩn bị dữ liệu huấn luyện, đến lúc xây dựng mô hình mạng nơ-ron. Các kĩ thuật mô hình hóa đa dạng được chọn lựa và áp dụng và các tham số của chúng được điều chỉnh đến giá trị tối ưu. Mục tiêu là sử dụng tất cả dữ liệu và thông tin được cung cấp trong các bước trước đó một cách tốt nhất có thể để tạo ra một mô hình có thể giải quyết vấn đề. Như trong mô hình này sẽ là dự đoán khách hàng có gặp khó khăn trong quá trình trả nợ hay không.
Kiến trúc mạng nơ-ron
Mô hình mạng nơ-ron phù hợp thường được lựa chọn thông qua việc phát triển và so sánh nhiều khả năng, chỉ giữ lại những khả năng tốt nhất. Sau khi mô hình được chọn, nó nên được thực hiện với các tham số cụ thể (số lượng đầu vào, đầu ra và lớp ẩn).
Lớp đầu vào: Số lượng nơ-ron sẽ mặc định bằng số lượng thuộc tính của bài toán.
Lớp đầu ra: Số lượng nơ-ron sẽ phụ thuộc vào bài toán. Trong bài toán phân loại nhiều lớp thì nó sẽ có nhiều nơ-ron. Còn bài toán này đơn thuần là một bài toán phân loại nhị phân nên đầu ra sẽ là 1 nơ-ron.
Số lượng lớp ẩn: Không có một công thức nhất định cho số lớp ẩn. Thông thường nó sẽ là khoảng hai đến năm lớp ẩn. Ta có thể thử cho đến mô hình không còn tăng các điểm số đánh giá nữa nhưng cũng cần lưu ý càng nhiều lớp ẩn thì càng tăng khả năng quá khớp (overfitting).
Số lượng nơ-ron: Cũng không có một công thức nhất định cho số nơ-ron trong từng lớp. Một cách phổ biến là giảm dần một nửa số nơ-ron sau từng lớp. Cần lưu ý việc nếu quá nhiều nơ-ron sẽ tốn tài nguyên cho huấn luyện và overfitting còn quá ít nơ-ron thì đôi khi sẽ không bao quát hết mô hình. Trong bài viết này, tác giả thử nghiệm thấy 64 nơ-ron ở lớp ẩn đầu tiên, cho kết quả tốt.
Xây dựng mạng nơ-ron
Để đạt hiệu quả tốt nhất khi huấn luyện, mô hình sử dụng hai hàm kích hoạt là ReLu và Sigmoid. Mô hình sử dụng thuật toán Adam làm thuật toán tối ưu hóa. Đây là một thuật toán tối ưu được tạo ra cho việc huấn luyện mạng nơ-ron sâu. Thuật toán này có hiệu quả rất cao trong tốc độ huấn luyện, nó có một biến là Learning Rate hay tỉ lệ học, tức là độ thay đổi của các trọng số và độ lệch sau mỗi chu kì. Sau khi thử thì độ lệch là 0.01, Learning Rate được chọn.
Huấn luyện mạng nơ-ron
Sau khi xây dựng mô hình, bước tiếp theo là huấn luyện mô hình học dựa trên tập dữ liệu huấn luyện để dự đoán khả năng trả nợ của khách hàng. Việc huấn luyện được tiến hành trên nền tảng Google Colab với cấu hình Intel(R) Xeon(R) CPU @ 2.20GHz và 12.7 GB ram. Thời gian để mô hình tính toán và điều chỉnh các trọng số trong nó là hơn 2.983 giây. (Hình 2)
Hình 2: Kết quả huấn luyện mô hình
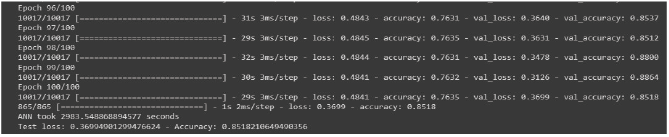
Nguồn: Tính toán của tác giả
4. Đánh giá hiệu suất mô hình
Để đánh giá hiệu suất mô hình, tác giả sử dụng điểm AUC (Area Under the Curve) là một phép đo tổng hợp về hiệu suất của phân loại nhị phân trên tất cả các giá trị ngưỡng có thể xảy ra. Để hiểu rõ hơn về độ đo này thì cần đề cập đến một định nghĩa khác liên quan đến nó là Confusion Matrix. (Hình 3)
Hình 3: Confusion Matrix
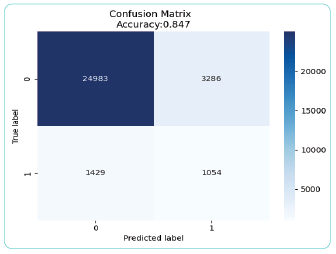
Nguồn: Tính toán của tác giả
Confusion Matrix là một bảng gồm bốn phần như sau:
- True Positive (TP): Số lượng các mẫu được dự đoán là Positive và thực tế cũng là Positive.
- True Negative (TN): Số lượng các mẫu được dự đoán là Negative và thực tế cũng là Negative.
- False Positive (FP): Số lượng các mẫu được dự đoán là Positive nhưng thực tế là Negative.
- False Negative (FN): Số lượng các mẫu được dự đoán là Negative nhưng thực tế là Positive.
Mô hình đã tự dự đoán và đưa ra độ chính xác (Accuracy) là 0,847. Giá trị Accuracy này được tính theo công thức sau:
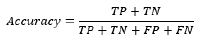
Điều đó có nghĩa là tỉ lệ dự đoán chính xác của mô hình là 84,7%. Tuy nhiên, độ chính xác này chỉ phản ánh trên dữ liệu đã biết trước. Để đánh giá mô hình một cách khách quan hơn, ta sử dụng AUC. AUC chính là ROC Curve hay đường cong ROC được tạo ra bằng cách vẽ hai giá trị sau:
True Positive Rate (TPR) - Tỉ lệ TP:
.PNG)
False Positive Rate (FPR) - Tỉ lệ FP:
.PNG)
Đường cong ROC được vẽ với TPR là trục tung, FPR là trục hoành. Đường cong ROC của mô hình được biểu thị ở Hình 4.
Hình 4: Đường cong ROC
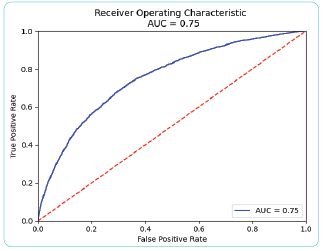
Nguồn: Tính toán của tác giả
AUC được tính bằng giá trị phần diện tích dưới đường cong trên tổng diện tích hình vuông tạo bởi TPR và FPR. Giá trị AUC càng gần 1 thì mô hình càng tốt. AUC có ưu điểm hơn Accuracy ở chỗ AUC không phụ thuộc vào độ lớn của bộ dữ liệu kiểm thử. Trong nghiên cứu này, tác giả đã sử dụng hàm tính AUC từ thư viện Keras và thu được kết quả xấp xỉ 0,75, một kết quả chấp nhận được.
5. Kết luận
Kết quả của nghiên cứu đã khẳng định sự hiệu quả của việc sử dụng phương pháp học sâu và xây dựng mô hình trên một bộ dữ liệu thực tế do Home Credit cung cấp, bao gồm thông tin về lịch sử tín dụng, thu nhập và một loạt các yếu tố quan trọng khác. Để cải thiện hiệu suất của mô hình, một phần quan trọng đã được dành cho quá trình tiền xử lí dữ liệu.
Trong quá trình tiền xử lí, những thuộc tính không quan trọng đã được loại bỏ, những thuộc tính không phải kiểu số đã được biến đổi để phù hợp với mô hình và dữ liệu đã được làm sạch để loại bỏ các giá trị bất thường và thiếu sót. Những bước này giúp tối ưu hóa dữ liệu đầu vào, từ đó cải thiện khả năng dự đoán của mô hình.
Kết quả của mô hình đã được đánh giá thông qua điểm số AUC đạt 0,75, một con số được chấp nhận trong việc dự đoán rủi ro tín dụng. Mô hình không chỉ giúp xác định những khách hàng có nguy cơ cao về vấn đề vỡ nợ mà còn cung cấp thông tin quan trọng để các TCTD có thể đưa ra quyết định về việc cấp tín dụng một cách minh bạch và chính xác hơn. Điều này đóng góp vào việc tối ưu hóa quản lí rủi ro và tăng cường tính ổn định của hệ thống tín dụng.
Tài liệu tham khảo:
1. Kolo, Brian, Thomas Rickett McGraw and Dathan Gaskill (2012). “Systems and methods for using data metrics for credit score analysis”. U.S. Patent Application 13/456,532.
2. C, elik, S, aban (2013). “Micro credit risk metrics: a comprehensive review”. Intelligent Systems in Accounting, Finance and Management 20, no. 4: pages 233-272.
3. Gorton, Gary, and James Kahn. ”The design of bank loan contracts”. The Review of Financial Studies 13, no. 2 (2000): pages 331-364.
4. “Home Credit Default Risk.” Kaggle, https://www.kaggle.com/c/homecredit-default-risk/data
5. J. Heaton (2015), “Artificial intelligence for humans, volume 3: Deep learning and neural networks”, T. Heaton, editor.
6. Langrehr, Virginia B., and Frederick W. Langrehr. ”Measuring the ability to repay: The residual income ratio”. Journal of Consumer Affairs 23, no. 2 (1989): pages 393-406.
7. M. Bahi and M. Batouche (2018), “Deep learning for ligand-based virtual screening in drug discovery”.
8. Mierzewski, Michael B., Christopher L. Allen, Jeremy W. Hochberg, and Kevin Hall (2013). “CFPB Finalizes Ability-to-Repay and Qualified Mortgage Rule”. Banking LJ 130: 611.
ThS. Nguyễn Thị Yến