Keywords: ML, risk management, credit risk.
1. Hệ thống hóa về ML
Khái niệm
Nhắc đến ML thì trước tiên phải nói tới AI. Theo McCarthy, 1998, AI là sản phẩm của khoa học và công nghệ nhằm làm cho máy móc có những khả năng của trí tuệ và trí thông minh con người, điển hình như biết suy nghĩ và lập luận để giải quyết vấn đề, biết giao tiếp do hiểu ngôn ngữ và tiếng nói, biết học và tự thích nghi. AI ra đời dẫn đến sự phát triển của khái niệm ML và kế tiếp là học sâu (Deep Learning - DL). Mô tả trực quan thì AI là vòng tròn lớn nhất, tiếp đến là vòng tròn ML và cuối cùng là vòng tròn nhỏ nhất DL. ML là việc ứng dụng các thuật toán để phân tích dựa trên dữ liệu lớn, học hỏi từ dữ liệu đó để thực hiện một quyết định hoặc dự đoán về các vấn đề có liên quan. (Hình 1)
Hình 1. Mô tả trực quan về AI, ML và DL
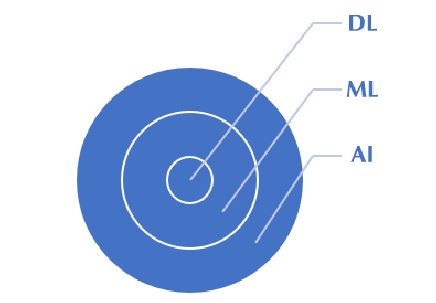 Nguồn: Goodfellow và cộng sự (2016)
Nguồn: Goodfellow và cộng sự (2016)
Theo Awad và Khanna (2015), ML là kết hợp của khoa học máy tính, kĩ thuật và thống kê. Nó đã được nhấn mạnh như một công cụ có thể được áp dụng cho các vấn đề khác nhau, đặc biệt là trong các lĩnh vực yêu cầu dữ liệu được diễn giải và cung cấp thông tin. ML có khả năng phát hiện các mẫu có ý nghĩa trong dữ liệu và đã trở thành một công cụ phổ biến cho bất kì nhiệm vụ nào phải đối mặt với yêu cầu trích xuất mẫu có ý nghĩa từ các tập dữ liệu. Khi đối mặt với yêu cầu trích xuất mẫu có ý nghĩa từ dữ liệu cùng sự phức tạp trong số các mẫu cần nghiên cứu, một lập trình viên có thể không thể cung cấp mô tả rõ ràng và chi tiết về quá trình thực hiện. ML giải quyết thách thức này bằng cách cung cấp cho các chương trình khả năng “học hỏi và thích ứng”. Các chương trình ML học hỏi, cải tiến và có thể được áp dụng khi vấn đề phải xử lí có thách thức kép về sự phức tạp và khả năng thích ứng. Nói một cách đơn giản, tính năng nổi bật khi nhắc đến ML là khả năng “tự học”, nghĩa là theo thời gian, không gian, với nhiều dữ liệu hơn, các thuật toán cho phép hệ thống tính toán “thông minh” hơn, từ đó “co hẹp” sai số và đưa ra kết quả chính xác hơn. Khi càng vận hành, hệ thống ứng dụng ML càng “tự học” được nhiều, càng “thông minh” hơn và ít phụ thuộc vào sự can thiệp của con người.
Ứng dụng
ML có ứng dụng rộng khắp trong các ngành khoa học, sản xuất, đặc biệt những ngành cần phân tích khối lượng dữ liệu khổng lồ. Một số ứng dụng thường thấy:
- Xử lí ngôn ngữ tự nhiên: Xử lí văn bản, giao tiếp người - máy...
- Nhận dạng: Nhận dạng tiếng nói, chữ viết tay, vân tay, thị giác...
- Các ứng dụng tìm kiếm.
- Chẩn đoán trong y tế: Phân tích ảnh X-quang, chẩn đoán tự động.
- Trong sinh học: Phân loại chuỗi gene, phân tích quá trình hình thành gene/protein.
- Vật lí: Phân tích ảnh thiên văn, tác động giữa các hạt...
- Phát hiện gian lận tài chính: Gian lận thẻ tín dụng...
- Phân tích thị trường chứng khoán.
- Chơi trò chơi: Tự động chơi cờ, điều khiển hành động của các nhân vật ảo.
- Robot: Là tổng hợp của rất nhiều ngành khoa học, trong đó ML tạo nên hệ thần kinh/bộ não của người máy.
Phương pháp
Học có giám sát (Supervised Learning): Là thuật toán dự đoán đầu ra (Outcome) của một dữ liệu mới (New input) dựa trên các cặp (Input, Outcome) đã biết từ trước. Cặp dữ liệu này còn được gọi là Data/Label tức dữ liệu/nhãn. Học có giám sát là nhóm phổ biến nhất trong các thuật toán ML. Ví dụ thuật toán dò các khuôn mặt trong một bức ảnh. Thời gian đầu, Facebook sử dụng thuật toán này để chỉ ra các khuôn mặt trong một bức ảnh và yêu cầu người dùng gán nhãn cho mỗi khuôn mặt. Số lượng cặp dữ liệu (khuôn mặt, tên người) càng lớn, độ chính xác ở những lần tự động tiếp theo sẽ càng lớn.
Học không giám sát (Unsupervised Learning): Thuật toán học không giám sát dựa vào cấu trúc của dữ liệu để thực hiện một công việc nào đó, ví dụ như phân nhóm hoặc giảm số chiều của dữ liệu để thuận tiện trong việc lưu trữ và tính toán. Ví dụ những khán giả xem phim Spider Man thường có xu hướng xem thêm phim Bat Man, dựa vào đó, ML tạo ra một hệ thống gợi ý khách hàng, thúc đẩy nhu cầu mua sắm.
Học củng cố (Reinforcement Learning): Là các bài toán giúp cho hệ thống tự động xác định hành vi dựa trên hoàn cảnh để đạt được lợi ích cao nhất. Hiện tại, học củng cố chủ yếu được áp dụng vào lí thuyết trò chơi (Game theory), các thuật toán cần xác định nước đi tiếp theo để đạt được điểm số cao nhất.
Một số thuật toán
Thuật toán Regression (Hồi quy): Liên quan đến việc mô hình hóa mối quan hệ giữa các biến. Các thuật toán hồi quy phổ biến nhất trong ML là: Ordinary Least Squares Regression (OLSR), Linear Regression, Logistic Regression, Stepwise Regression, Multivariate Adaptive Regression Splines (MARS), Locally Estimated Scatterplot Smoothing (LOESS)...
Thuật toán Instance-based (Dựa trên mẫu): Gồm k-Nearest Neighbor (kNN), Learning Vector Quantization (LVQ), Self-Organizing Map (SOM), Locally Weighted Learning (LWL)...
Thuật toán Linear Regression (Hồi quy tuyến tính): Gồm Ridge Regression, Least Absolute Shrinkage and Selection Operator (LASSO), Elastic Net, Least-Angle Regression (LARS)...
Thuật toán Support Vector Machine - SVM (Máy vector hỗ trợ): SVM là một thuật toán thuộc nhóm học có giám sát được sử dụng rất phổ biến trong các bài toán phân lớp hay hồi quy. SVM dựa trên lí thuyết học thống kê do Vapnik và Chervonenkis (1995) xây dựng. Tư tưởng của SVM là tìm ra một siêu mặt phẳng có thể phân tách các tập dữ liệu cần phân loại sao cho khoảng cách từ siêu mặt phẳng đến các tập cần phân loại là tương đương nhau và lớn nhất.
Thuật toán Decision Tree (Cây quyết định): Là một mô hình thuộc nhóm thuật toán học có giám sát. Cây quyết định là một cây phân cấp có cấu trúc được dùng để phân lớp các đối tượng dựa vào hàng loạt các quy tắc. Khi cho dữ liệu về các đối tượng gồm các thuộc tính cùng với lớp của nó, cây quyết định sẽ sinh ra các quy tắc để dự đoán lớp của các đối tượng chưa biết. Thuật toán này gồm Classification và Regression Tree (CART), Iterative Dichotomiser 3 (ID3), 5 and C5.0 (different versions of a powerful approach), Chi-squared Automatic Interaction Detection (CHAID), Decision Stump, M5, Conditional Decision Trees...
Thuật toán Bayesian (Phân lớp): Gồm Naive Bayes, Gaussian Naive Bayes, Multinomial Naive Bayes, Averaged One-Dependence Estimators (AODE), Bayesian Belief Network (BBN), Bayesian Network (BN)...
Thuật toán Clustering (Phân cụm): Giống như hồi quy, mô tả lớp vấn đề và lớp phương thức, thuật toán này được tổ chức theo các phương pháp mô hình hóa. Tất cả các phương pháp đều liên quan đến việc sử dụng các cấu trúc vốn có trong dữ liệu. Đó là một nhu cầu tổ chức tốt nhất dữ liệu thành các nhóm phổ biến tối đa. Bao gồm k-Means, k-Medians, Expectation Maximisation (EM), Hierarchical Clustering...
Thuật toán quy tắc kết hợp: Trích xuất quy tắc, giải thích tốt nhất mối quan hệ giữa các biến trong dữ liệu. Các quy tắc này có thể khám phá sự kết hợp quan trọng và hữu ích trong các bộ dữ liệu đa chiều lớn. Điều đó có thể được khai thác bởi một tổ chức. Các thuật toán quy tắc kết hợp phổ biến gồm thuật toán Apriori, Eclat.
Thuật toán mạng nơ-ron nhân tạo: Là những mô hình được lấy cảm hứng từ cấu trúc của mạng nơ-ron sinh học. Các thuật toán mạng nơ-ron nhân tạo phổ biến nhất là Perceptron, Back-Propagation, Hopfield Network, Radial Basis Function Network (RBFN)...
Thuật toán DL: Là một bản cập nhật hiện đại cho mạng nơ-ron nhân tạo. Các thuật toán DL phổ biến nhất là: Deep Boltzmann Machine (DBM), Deep Belief Networks (DBN), Convolutional Neural Network (CNN), Stacked Auto-Encoders...
Thuật toán giảm kích thước tìm kiếm cấu trúc vốn có trong dữ liệu: Bao gồm Principal Component Analysis (PCA), Principal Component Regression (PCR), Partial Least Squares Regression (PLSR), Sammon Mapping, Multidimensional Scaling (MDS), Projection Pursuit, Linear Discriminant Analysis (LDA), Mixture Discriminant Analysis (MDA), Quadratic Discriminant Analysis (QDA), Flexible Discriminant Analysis (FDA)...
Thuật toán tập hợp: Thuật toán tập hợp các mô hình: Boosting, Bootstrapped Aggregation (Bagging), AdaBoost, Stacked Generalization (blending), Gradient Boosting Machines (GBM), Gradient Boosted Regression Trees (GBRT), Random Forest...
2. Áp dụng ML trong quản trị rủi ro tín dụng của ngân hàng
Rủi ro tín dụng là khả năng khách hàng không trả được nợ theo thỏa thuận ban đầu. Vì tỉ trọng tín dụng là đáng kể trong danh mục tài sản của hầu hết các ngân hàng nên việc khách hàng không trả được nợ sẽ ảnh hưởng trực tiếp đến kết quả kinh doanh và tiềm năng phát triển trong tương lai của ngân hàng. Để kiểm soát rủi ro tín dụng nhằm hạn chế tổn thất, các ngân hàng cần không ngừng cải thiện năng lực quản trị rủi ro để có thể đo lường chính xác nhất khả năng khách hàng không trả được nợ. Đặc biệt, sau các sự kiện khủng hoảng tài chính toàn cầu và với sự gia tăng các quy định đối với hoạt động ngân hàng, quy trình đánh giá rủi ro tín dụng đã nhận được sự quan tâm ngày càng lớn về cả học thuật và thực tiễn. Các công nghệ mới nói chung và ML nói riêng đã dần được nghiên cứu để áp dụng trong quản trị rủi ro tín dụng của ngân hàng và các tổ chức cung cấp dịch vụ tín dụng.
Trước tiên, ML phát huy tác dụng trong sàng lọc những người nộp đơn xin vay có khả năng vỡ nợ thấp nhất trong hàng nghìn đề xuất vay vốn mà các ngân hàng nhận được. Theo S. Z. H. Shoumo và cộng sự (2019), ML có thể được áp dụng trong trường hợp này để phát triển một mô hình có khả năng hiểu và học hỏi từ hành vi của những khách hàng thành công và những người vỡ nợ. Khi có người nộp đơn xin vay mới, mô hình có thể dự đoán chính xác khả năng vỡ nợ của người nộp đơn dựa trên các mẫu mà nó đã học trước đó và các tổ chức tín dụng như ngân hàng hoặc công ty cho vay khác sử dụng kết quả này để ra quyết định có chấp nhận yêu cầu vay của người nộp đơn hay không. Khashman, A. (2010) mô tả một hệ thống đánh giá rủi ro tín dụng sử dụng mô hình mạng nơ-ron được giám sát dựa trên thuật toán học lan truyền ngược. Tác giả đưa ra mô hình ba mạng lưới nơ-ron để quyết định chấp thuận hay từ chối đơn xin vay. Các mạng nơ-ron được đào tạo bằng cách sử dụng bộ dữ liệu phê duyệt vay vốn ngân hàng ở Đức gồm 1.000 trường hợp (700 trường hợp người nộp đơn đáng tin cậy “good” hoặc “accept” và 300 trường hợp không đáng tin cậy “bad” hoặc “reject”), mỗi trường hợp có 24 thuộc tính số để quyết định mỗi đơn xin vay được chấp nhận hoặc từ chối. Kết quả là tỉ lệ chính xác trong tổng thể ra quyết định cấp tín dụng là 83,6%; quá trình huấn luyện mô hình nơ-ron này được hoàn thành trong khoảng 184 giây, trong khi thời gian đưa ra quyết định cho mô hình nơ-ron được huấn luyện là rất nhanh. Hamid, A. J. và Ahmed, T. M. (2016) đã sử dụng thuật toán Bayes Net, Nave Bayes và cây quyết định cho mục đích này. Dựa trên các đặc điểm của người vay như giới tính, lịch sử tín dụng, nghề nghiệp, mục đích vay, tuổi, loại nhà ở và số tiền vay để dự đoán liệu người nộp đơn mới có trở thành người không trả được nợ hay không. Theo nghiên cứu này, thuật toán cây quyết định là lựa chọn ưa thích của họ với độ chính xác là 78,3784%.
ML được chứng minh là vượt trội hơn các phương pháp truyền thống về dự đoán rủi ro tín dụng thông qua so sánh giữa ứng dụng các thuật toán của ML và các phương pháp truyền thống. Nhiều nghiên cứu đã so sánh với các phương pháp thống kê truyền thống để làm nổi bật tính hiệu quả trong việc áp dụng các thuật toán ML. Galindo và Tamayo (2000) khẳng định rằng, cách duy nhất đánh giá rủi ro của các trung gian tài chính là thông qua việc tìm kiếm các yếu tố dự báo đáng tin cậy của rủi ro riêng lẻ trong danh mục tín dụng. Họ đã so sánh các kĩ thuật phân loại thống kê và ML bằng cách xây dựng hơn 9.000 mô hình và so sánh hoạt động của các thuật toán khác nhau. Bằng cách sử dụng các thuật toán ML khác nhau để phân loại dữ liệu cho vay thế chấp, nghiên cứu đã phát hiện ra rằng, các thuật toán cây quyết định cung cấp ước tính tốt nhất về khả năng vỡ nợ với tỉ lệ lỗi trung bình là 8,13%; mạng nơ-ron nhân tạo cung cấp kết quả tốt thứ hai với sai số trung bình là 11%; tiếp theo là thuật toán kNN và thuật toán Probit. Bekhet, H. A. và Eletter, S. F. K. (2014) đã sử dụng mạng nơ-ron nhân tạo chuyển tiếp nguồn cấp dữ liệu đa lớp và so sánh với mô hình hồi quy Logistic. Họ dùng bộ dữ liệu gồm 492 trường hợp được thu thập từ các ngân hàng thương mại Jordan. Kết quả cho thấy mô hình hồi quy chính xác hơn trong việc phân loại đúng các đơn xin vay được chấp nhận và mạng nơ-ron nhân tạo có lợi thế hơn trong việc phân loại các trường hợp khách hàng bị từ chối. Hamori và cộng sự (2018) đã nghiên cứu và so sánh độ chính xác của các dự đoán và khả năng phân loại của mạng nơ-ron nhân tạo trong phân tích dữ liệu mất khả năng thanh toán. Họ cũng thấy sự ưu việt của các phương pháp ML. Nguyễn Minh Kiều và cộng sự (2017) nghiên cứu thực nghiệm dựa trên việc thu thập dữ liệu từ các bộ hồ sơ trong quá khứ của các ngân hàng: Ngân hàng Thương mại cổ phần (NHTMCP) Ngoại thương Việt Nam (Vietcombank), NHTMCP Công thương Việt Nam (VietinBank), NHTMCP Sài Gòn Thương tín (Sacombank), NHTMCP Đông Á (DongA Bank), NHTMCP Quân đội (MB) từ năm 2012 - 2014, ứng dụng mô hình mạng nơ-ron nhân tạo có giám sát dựa trên các thuật toán học truyền lại với mục đích đào tạo để quyết định việc chấp thuận hoặc từ chối việc cấp tín dụng. Dựa trên kết quả nghiên cứu cho thấy, mô hình mạng nơ-ron nhân tạo đem lại hiệu quả trong việc hỗ trợ ra quyết định cấp tín dụng một cách nhanh chóng và đơn giản với tỉ lệ chính xác của dự báo đến 95,45%. Kết quả của nghiên cứu cũng tương đồng với kết quả của Vita Jagric, Davorin Kracun và Timotej Jagric (2011), Adnan Khashman (2010)... trong kết luận, mạng nơ-ron nhân tạo hỗ trợ ra quyết định nhanh chóng với độ chính xác cao.
Các nghiên cứu về các kĩ thuật chấm điểm tín dụng được thấy nhiều ở các nghiên cứu trong lĩnh vực này (Ala’raj và Abbod, 2016; Bellotti và Crook, 2009; Cao và cộng sự, 2013; Wang và cộng sự, 2015; Wójcicka, 2017). Các nghiên cứu này đa phần tập trung vào phân loại và ứng dụng các thuật toán chấm điểm tín dụng. Các nghiên cứu nhìn chung đều kết luận rằng, ML mang lại độ chính xác tương đương và được trang bị tốt hơn để nắm bắt các mối quan hệ phi tuyến tính phổ biến của rủi ro tín dụng. Các kĩ thuật như hồi quy Logistic và phân tích biệt số (Discriminal Analysis) thường được sử dụng trong chấm điểm tín dụng để xác định khả năng vỡ nợ. SVM đã thành công trong việc phân loại những khách hàng không trả được nợ và đã được chứng minh là mang lại kết quả tốt hơn đáng kể trong việc chấm điểm tín dụng (Van Gestel và cộng sự, 2003). Thuật toán này cũng được cho là cạnh tranh trong việc khám phá các đặc điểm quan trọng nhất của việc xác định rủi ro vỡ nợ khi được kiểm tra và so sánh với các kĩ thuật truyền thống (Bellotti và Krook, 2009). Trong các kĩ thuật được sử dụng chấm điểm tín dụng, chẳng hạn như phân tích biệt số, hồi quy logistic, mạng nơ-ron nhân tạo và cây quyết định thì mạng nơ-ron nhân tạo đã được chứng minh là thực hiện phân loại chính xác hơn các phương pháp còn lại (Yeh và Lien 2009). Harris (2013) so sánh các mô hình chấm điểm tín dụng dựa trên SVM sử dụng định nghĩa rộng (ngày quá hạn<90 ngày) và định nghĩa hẹp (ngày quá hạn>90 ngày) thì thấy rằng các mô hình được xây dựng bằng cách sử dụng định nghĩa rộng hơn sẽ chính xác hơn, từ đó cho phép cải thiện độ chính xác của dự đoán.
ML cũng được áp dụng để kiểm tra sức chịu đựng (Stress test) trong quản lí rủi ro tín dụng (Islam và cộng sự, 2013). Stress test đòi hỏi mô hình hóa mối liên kết giữa các biến thể hiện phát triển kinh tế vĩ mô và các biến về nghiệp vụ ngân hàng để xác định tác động của các kịch bản cực đoan đối với ngân hàng. Thuật toán hồi quy Lasso thích ứng trong phương pháp học có giám sát được sử dụng trong trường hợp không có các mô hình lí thuyết để kiểm tra sức chịu đựng từ trên xuống từ một tập hợp hàng ngàn thông số kĩ thuật. Nó đã được chứng minh là cung cấp các giải pháp không chệch và xấp xỉ bằng cách tìm kiếm các biến mô tả hành vi của tỉ lệ tổn thất tín dụng tốt nhất, cung cấp mô tả rõ ràng về mối quan hệ giữa tỉ lệ tổn thất tín dụng và kinh tế vĩ mô. Một vấn đề quan trọng khi áp dụng thuật toán này là cần có lượng dữ liệu lớn để đào tạo mô hình (Blom, 2015). Lựa chọn mô hình và dự báo trở thành thách thức khi các kịch bản căng thẳng trở nên toàn diện hơn với số lượng các biến cơ sở ngày càng tăng. Kĩ thuật ML để xác định các mẫu và mối quan hệ giữa dữ liệu có thể tạo điều kiện thuận lợi cho việc lựa chọn mô hình và dự báo. Những kĩ thuật này dường như chưa được áp dụng rộng rãi trong các thử nghiệm sức chịu đựng. Khi có một số lượng lớn các đồng biến tiềm năng và số lượng quan sát là nhỏ, hồi quy Lasso được cho là phù hợp để xây dựng mô hình dự báo. Các mô hình này vượt trội so với các mô hình thống kê truyền thống trong việc dự báo các chỉ số hoạt động cần thiết trong thử nghiệm sức chịu đựng. Chúng cũng có thể xử lí các biến chứng phát sinh trong các bài kiểm tra sức chịu đựng (Chan-Lau, 2017). Thêm nữa, thuật toán Multivariate Adaptive Regression Splines (MARS), một kĩ thuật ML khác cũng thể hiện độ chính xác cao hơn trong kiểm tra sức chịu đựng với mẫu vượt trội, đem lại các dự báo hợp lí hơn (Jacobs, 2018). Đồ thị xác suất có thể được sử dụng để mô hình hóa và đánh giá rủi ro tập trung tín dụng với thuật toán mạng Bayesian đem lại sự hiểu biết tốt hơn về rủi ro. Thuật toán này cũng được tìm thấy là phù hợp để phân tích thử nghiệm sức chịu đựng, có thể cung cấp ước tính về khả năng xảy ra tổn thất do những thay đổi trong tình trạng tài chính của người vay (Pavlenko và Chernyak, 2009).
3. Kết luận
Có thể thấy, ML hữu ích trong quản trị rủi ro tín dụng của ngân hàng, đặc biệt là hai giai đoạn đầu trong quy trình quản trị rủi ro là nhận diện và đo lường. Việc áp dụng ML quản trị rủi ro nói chung và quản trị rủi ro tín dụng nói riêng là tất yếu. Tuy nhiên, các thách thức để áp dụng là không nhỏ. Chẳng hạn, thách thức về chất lượng của dữ liệu. Dữ liệu là một trong những thành phần quan trọng nhất của mô hình ML do hiệu suất của mô hình tương quan trực tiếp với chất lượng dữ liệu mà nó được cung cấp. Khi nói đến việc sử dụng AI nói chung và ML nói riêng thì điều cần thiết là tăng hệ số tin cậy cho hiệu suất của mô hình bằng cách đảm bảo rằng dữ liệu được sử dụng là rất lớn, đa dạng và được cập nhật thường xuyên. Không nên xem nhẹ quá trình thu thập dữ liệu vì việc xây dựng một bộ dữ liệu chất lượng cao đòi hỏi rất nhiều thời gian và công sức. Vấn đề về bảo mật dữ liệu cũng là một thách thức mà các ngân hàng phải vượt qua. Một lượng lớn dữ liệu được sử dụng trong các mô hình này có thể được coi là rất nhạy cảm. Tên, tuổi, địa chỉ, số thẻ tín dụng, tài khoản ngân hàng và các thông tin khác của khách hàng có thể được bao gồm trong dữ liệu đó. Trong những trường hợp này, vi phạm dữ liệu sẽ gây nguy hiểm cho quyền riêng tư cá nhân của khách hàng, đồng thời cho phép kẻ tấn công truy cập vào tài sản tài chính của họ. Để giải quyết vấn đề này, cần phải thực hiện thêm các biện pháp phòng ngừa bảo mật để ngăn dữ liệu nhạy cảm rơi vào tay kẻ xấu. Tiếp theo không thể không nói đến thách thức về pháp lí. Đây là vấn đề đã được nhắc đến rất nhiều kể từ khi các công nghệ tài chính mới lan rộng và được áp dụng trong cung ứng các dịch vụ tài chính, ngân hàng.
TÀI LIỆU THAM KHẢO:
1. Adnan Khashman (2010). Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes, Volume 37, Issue 9, pages 6233 - 6239.
2. Ala’raj, Maher, and Maysam F. Abbod. 2016a. A New Hybrid Ensemble Credit Scoring Model Based on Classifiers Consensus System Approach. Expert Systems with Applications 64, pages
36 - 55.
3. Awad, Mariette, and Rahul Khanna (2015). Machine Learning in Action: Examples. Efficient Learning Machines.
4. Bacham, Dinesh, and Janet Zhao (2017). Machine Learning: Challenges and Opportunities in Credit Risk Modeling, https://www.moodysanalytics.com/risk-perspectives-magazine/managing-disruption/spotlight/machine-learning-challenges-lessons-and-opportunities-in-credit-risk-modeling
5. Bellotti, Tony, and Jonathan Crook (2009). Support Vector Machines for Credit Scoring and Discovery of Significant Features. Expert Systems with Applications.
6. Bekhet, H. A. and Eletter, S. F. K (2014). Credit risk assessment model for jordanian commercial banks: neural scoring approach. Review of Development Finance, Universiti Tenaga Nasional (UNITEN), 43000 Kajang, Selangor, Malaysia, 4(1), pages 20 - 28.
7. Blom, Tineke (2015). Top down Stress Testing: An Application of Adaptive Lasso to Forecasting Credit Loss Rates. Master’s Thesis, Faculty of Science, Hongkong, China.
8. Chan-Lau, Jorge (2017). Lasso Regressions and Forecasting Models in Applied Stress Testing. IMF Working papers 17: 1.
9. Cao, Jie, Hongke Lu, Weiwei Wang, and Jian Wang (2013). A Loan Default Discrimination Model Using Cost-Sensitive Support Vector Machine Improved by PSO. Information Technology and Management 14, pages 193 - 204.
10. Jacobs, Michael, Jr (2018). The validation of machine-learning models for the stress testing of credit risk. Journal of Risk Management in Financial Institutions 11, pages 218 - 43.
11. Hamid, A. J. and Ahmed, T. M. (2016). Developing prediction model of loan risk in banks using data mining. Machine Learning and Applications: An International Journal, University Khartoum, Sudan, 3(1), pages 1 - 9.
12. Hamori, Shigeyuki, Minami Kawai, Takahiro Kume, Yuji Murakami, and Chikara Watanabe (2018). Ensemble Learning or Deep Learning? Application to Default Risk Analysis. Journal of Risk and Financial Management 11:12.
13. Harris, Terry (2013). Quantitative credit risk assessment using support vector machines: Broad versus Narrow default definitions. Expert Systems with Applications 40: 4404 - 13.
14. Islam, Tushith, Christos Vasilopoulos, and Erik Pruyt (2013). Stress-Testing Banks under Deep Uncertainty. Paper presented at the 31st International Conference of the System Dynamics Society, Cambridge, MA, USA, July 21 - 25, http://repository.tudelft.nl/islandora/object/uuid:c162de43-4235-4d29-8eed-246df87e119?collection=education
15. Galindo, Jorge, and Pablo Tamayo (2000). Credit Risk Assessment Using Statistical and Machine Learning: Basic Methodology and Risk Modeling Applications. Computational Economics 15: 107 - 43
16. Goodfellow, I., Bengio, Y., Courville, A., & Bengio, Y. (2016). Deep learning (Vol. 1, No. 2). Cambridge: MIT press.
17. Khashman, A. (2010). Neural networks for credit risk evaluation: Investigation of different neural models and learning schemes. Expert Systems with Applications, 37(9), pages 6233 - 6239.
18. Nguyễn Minh Kiều, Nguyễn Thị Ngọc Diệp, Nguyễn Thị Hằng Nga, Nguyễn Kim Nam (2017), Ứng dụng mô hình mạng thần kinh nhân tạo để ước lượng rủi ro tín dụng ở các ngân hàng thương mại Việt Nam, Tạp chí Ngân hàng số 11 tháng 6/2017.
19. McCarthy, J (1998). What is artificial intelligence?
20. Pavlenko, Tatjana, and Oleksandr Chernyak (2009). Bayesian Networks for Modeling and Assessment of Credit Concentration Risks. International Statistical Conference Prague, http://www.czso.cz/conference2009/proceedings/data/methods/pavlenko_paper.pdf
21. Shalev-Shwartz, Shai, and Shai Ben-David (2014). Understanding Machine Learning: From Theory to Algorithms. Cambridge: Cambridge University Press.
22. S. Z. H. Shoumo, M. I. M. Dhruba, S. Hossain, N. H. Ghani, H. Arif and S. Islam (2019). “Application of Machine Learning in Credit Risk Assessment: A Prelude to Smart Banking,” TENCON 2019 - 2019 IEEE Region 10 Conference (TENCON), Kochi, India, pages 2023 - 2028.
23. Van Gestel, Ir Tony, Bart Baesens, Ir Joao Garcia, and Peter Van Dijcke (2003). A support vector machine approach to credit scoring. In Forum Financier-Revue Bancaire Et Financiaire Bank En Financiewezen. Bruxelles: Larcier, pages 73 - 82.
24. Vita Jagric, Davorin Kracun và Timotej Jagric (2011). Does non-linearity matter in retail credit risk modeling?, volume 61, issue 4, pages 384 - 402.
25. Yeh, I. Cheng, and Chehui Lien (2009). The Comparisons of Data Mining Techniques for the Predictive Accuracy of Probability of Default of Credit Card Clients. Expert Systems with Applications.
26. Zhang, Wenhao (2017). Machine Learning Approaches to Predicting Company Bankruptcy. Journal of Financial Risk Management 6: 364 - 74.
27. Wang, Hong, Qingsong Xu, and Lifeng Zhou (2015). Large Unbalanced Credit Scoring Using Lasso-Logistic Regression Ensemble. PLoS ONE 10: e0117844.
28. Wójcicka, Aleksandra (2017). Neural Networks vs. Discriminant Analysis in the Assessment of Default. Electronic Economy, 339 - 49.
Trương Thị Hoài Linh
Đại học Kinh tế Quốc dân